In case you didn’t know, countries occasionally change their time zones, or alter the way they handle daylight saving time (DST). To let the database know about these changes we have to apply a new database time zone file. The updated files have been shipped with upgrades and patches since 11gR2, but applying them to the database has always been a manual operation.
With the recent switch over to daylight savings time in the UK I decided to post this question on Twitter yesterday.
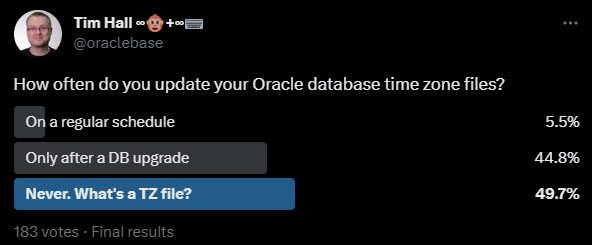
How often do you update your Oracle database time zone files?
We get less than 6% of people updating their time zone files on a regular schedule. Nearly 45% who only do the updates after a database upgrade, and nearly 50% of people who never do it at all.
I can’t say I’m surprised by the results. In terms of the reasoning for these responses, I’ll reference some of the comments on Twitter.
Regular Schedule
“Every ru patch, also thanks to 19.18 it is included now and with out of place upgrade and autoupgrade, i dont do it anymore 🙂 all automatic.”
If you are using AutoUpgrade to patch to a new Oracle Home, then applying updated time zone files is really easy. Before 19.18 it’s just a single entry “timezone_upg=yes” in the AutoUpgrade config file. From 19.18 onward the update of the time zone file is the default action (see here).
So interestingly, there may be some people who don’t know they are applying an update of their time zone file, who actually are now…
After Upgrades
This feels like the natural time to do it for me, and it seems many other people feel the same.
As mentioned previously, AutoUpgrade makes it simple. From 21c onward AutoUpgrade is the main upgrade approach, even for those that have resisted using it for previous versions, so this question goes away from an upgrade perspective.
We can specifically tell it not to perform the action using “timezone_upg=no”, but I’m guessing most people will just go with the default action.
Never
“NEVER. As an American-only company with very little need for time-specific data, quite unnecessary. Horrible design with no rollbacks and headaches w/data pump. Just not worth it if possible to avoid”
I totally understand this response. Many of us work with systems that are limited to our own country. Assuming our country doesn’t alter its own daylight savings time rules, then using an old time zone file is unlikely to cause an issue.
When you consider the number of people that run *very old* versions of Oracle, you can see that using old versions of the time zone file doesn’t present a major issue in these circumstances.
With reference to the data pump issue, I’ve experienced this, and it was also picked up in the comments.
“My hypothesis: Most do it when datapump tells they need to do it to get the import file they just received to load”
The point about this being an offline operation was raised.
“Well it is an offline operation, so pretty exceptional thing to do. Only in a rare case where some feature requires the upgrade – like DataPump failing or query over dblink failing.”
It seems like the time zone file version is not high on the list of priorities for most people, providing it is not causing a data pump issue. I totally understand this, and I myself only consider it during database upgrades.
I always like reading these poll results. I know the sample size is small, but it gives you a good idea of how your beliefs compare to the wider audience.
If you are interested to know how to manually upgrade your time zone file, you can read about it here.
I’ve been having a play with ChatGPT over the last few weeks, and I wanted to give a little example of using it to try and write some PL/SQL code. Importantly, I wanted to know how close it would get to generating runnable code against an Oracle database.
Calling a web service from PL/SQL
Let’s start by asking it a pretty straight forward question.
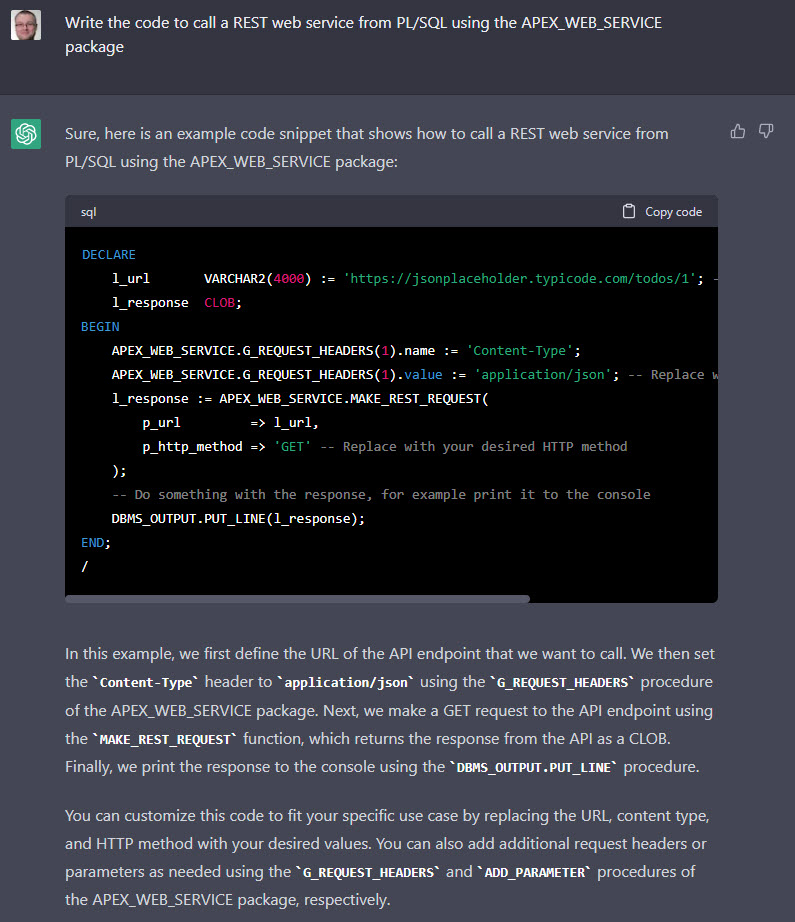
Question: Write the code to call a REST web service from PL/SQL using the APEX_WEB_SERVICE package
I think that’s pretty impressive, and not much different to my own example on the website. If someone gave me that answer in an interview question I would think they had done a reasonable job, but does it work? Not without some additional stuff.
What about the network ACL?
The first issue is it doesn’t mention we need to create a network ACL to allow us to make a callout from the database.
Does ChatGPT understand we need an ACL? Let’s see. I ask it about the ACL, and it gives me an explanation of using an ACL.
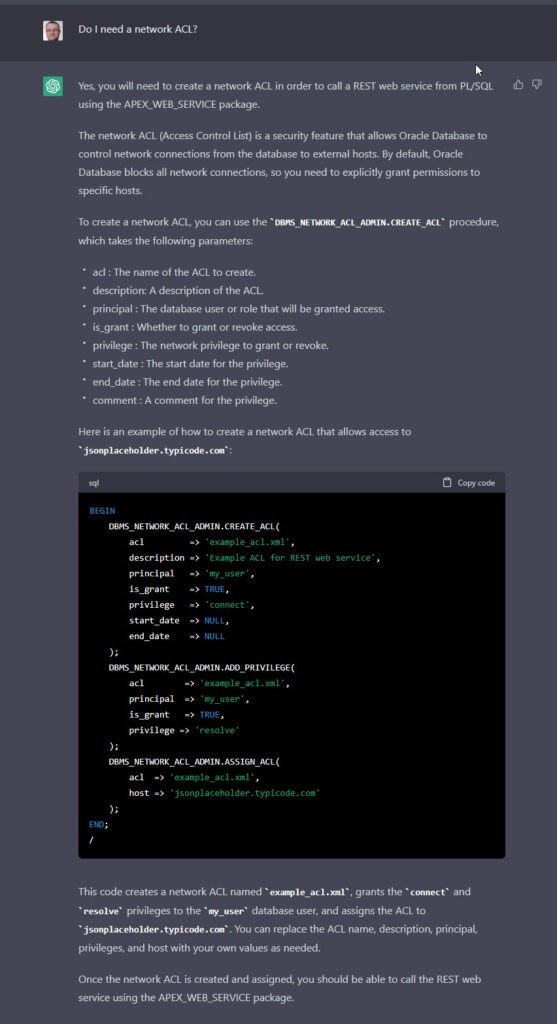
Question: Do I need a network ACL?
It’s using the pre-12c syntax, but let’s create it with the correct values.
conn sys/SysPassword1@//localhost:1521/pdb1 as sysdba
BEGIN
DBMS_NETWORK_ACL_ADMIN.CREATE_ACL(
acl => 'jsonplaceholder.typicode.com_acl.xml',
description => 'Example ACL for REST web service',
principal => 'APEX_220200',
is_grant => TRUE,
privilege => 'connect',
start_date => NULL,
end_date => NULL
);
DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE(
acl => 'jsonplaceholder.typicode.com_acl.xml',
principal => 'APEX_220200',
is_grant => TRUE,
privilege => 'resolve'
);
DBMS_NETWORK_ACL_ADMIN.ASSIGN_ACL(
acl => 'jsonplaceholder.typicode.com_acl.xml',
host => 'jsonplaceholder.typicode.com'
);
END;
/
I would normally prefer to use the 12c+ syntax, shown below, but we will continue with what ChatGPT suggests rather than using the newer syntax.
The next issue is it doesn’t tell us to create a wallet to hold the root certificate for the URL. It’s using a HTTPS address, so I have to use a wallet. I downloaded the root certificate from the site and put it in the “/tmp” location on the database server, then created the wallet as follows.
Because it didn’t tell me the wallet was needed, it also neglected to tell me the P_WALLET_PATH parameter was necessary in the MAKE_REST_REQUEST call.
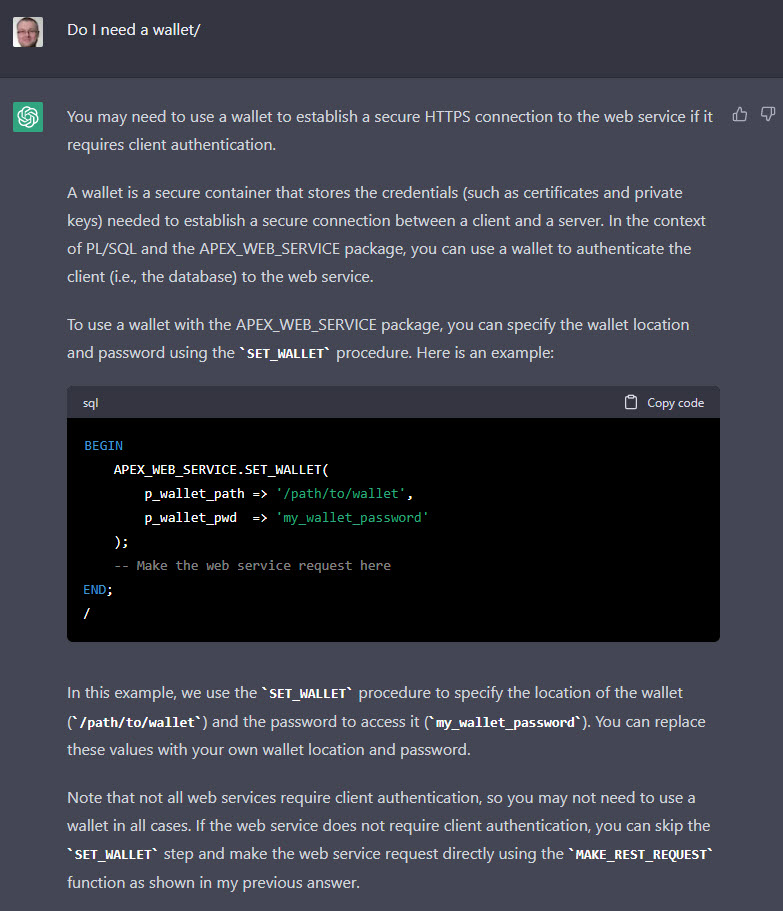
Does ChatGPT understand we need a wallet? I ask it about the wallet, and include a typo. 🙂 It didn’t care about the typo, and still gave us an answer. It doesn’t tell us how to create the wallet itself, and it thinks the SET_WALLET procedure is in the APEX_WEB_SERVICE package, but it’s in the UTL_HTTP package.
Question: Do I need a wallet?
I feel like that is a fail. Not only did is get the wrong package name, but we would typically use the P_WALLET_PATH parameter with APEX_WEB_SERVICE. Even so, it might give us a clue about where to look next.
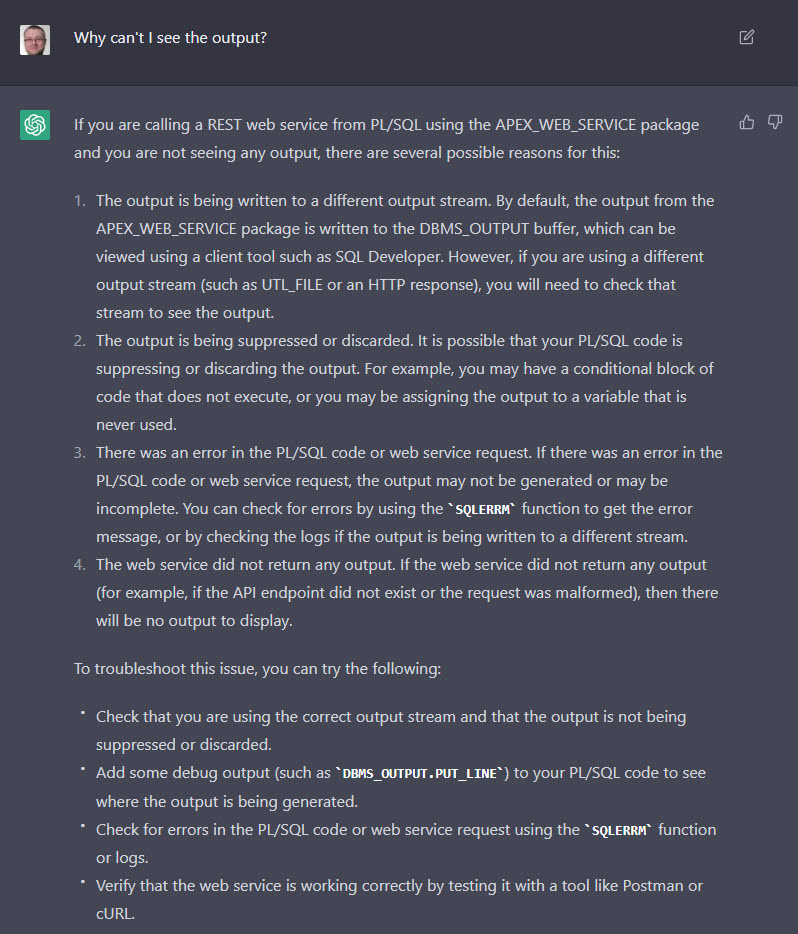
What about the output from the DBMS_OUTPUT package?
Finally, it didn’t tell use to turn on serveroutput to display the output from the DBMS_OUTPUT.PUT_LINE call. If this code was called from an IDE that might not matter, but from SQL*Plus or SQLcl it’s important if we want to see the result. I asked ChatGPT why I couldn’t see the output and it produced a lot of text, that kind-of eluded to the issue, but didn’t flat out tell us what to do.
Question: Why can’t I see the output?
Did the final solution work?
With the ACL and wallet in place, adding the P_WALLET_PATH parameter to the MAKE_REST_REQUEST call and turning on serveroutput, the answer is yes.
conn testuser1/testuser1@//localhost:1521/pdb1
set serveroutput on
DECLARE
l_url VARCHAR2(4000) := 'https://jsonplaceholder.typicode.com/todos/1'; -- Replace with your API endpoint
l_response CLOB;
BEGIN
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).name := 'Content-Type';
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).value := 'application/json'; -- Replace with your desired content type
l_response := APEX_WEB_SERVICE.MAKE_REST_REQUEST(
p_url => l_url,
p_http_method => 'GET', -- Replace with your desired HTTP method
p_wallet_path => 'file:/u01/wallet'
);
-- Do something with the response, for example print it to the console
DBMS_OUTPUT.PUT_LINE(l_response);
END;
/
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
PL/SQL procedure successfully completed.
SQL>
Thoughts
Overall it is pretty impressive. Is it perfect? No.
The interesting thing is we can ask subsequent questions, and it understands that these are in the context of what came before, just like when we speak to humans. This process of asking new questions allows us to refine the answer.
Just as we need some “Google-fu” when searching the internet, we also need some “ChatGPT-fu”. We need to ask good questions, and if we know absolutely nothing about a subject, the answers we get may still leave us confused.
We get no references for where the information came from, which makes it hard to fact check. The Bing integration does include references to source material.
Currently ChatGPT is based around a 2021 view of the world. It would be interesting to see what happens when this is repeated with the Bing integration, which does live searches of Bing for the base information.
When we consider this is AI, and we remember this is the worst it is ever going to be, it’s still very impressive.
Day 2 started pretty much the same as day 1. I arrived late to avoid the traffic.
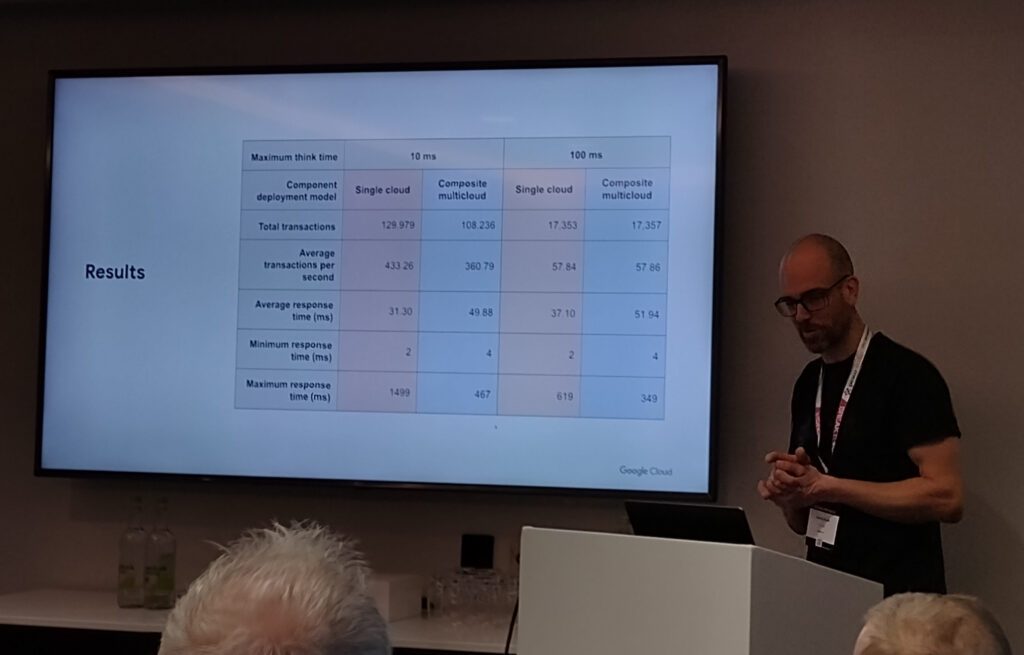
The first session I went to was Martin Nash with “Oracle Databases in a Multicloud World”. I was a bit late to this session, but from what I saw it seemed the general view was “don’t be stupid, stupid”. Multi-cloud can add some complexity and latency, but if it’s what you need, it’s all manageable. If you do have a system where multi-cloud is not suitable, don’t do it for that system. Most things can be migrated, but some things are easier than others. Pick your fights. Sorry if I came to the wrong conclusion… 🙂
I often get the feeling that some people think everything has to be all or nothing. We have Oracle Cloud Apps on Oracle Cloud. A bunch of stuff on Azure, with more to come. One of our major systems is moving to AWS in the next couple of years. Then of course we still have a load of stuff on-prem. This isn’t because we are desperate to be multi-cloud. It’s just the way things have happened. I’m sure we’ll run into some issue along the way, but I’m also sure we’ll solve them. Once size does not fit all…
BTW Martin now works for Google, so we have to hate him. 🙂
Next up was Jasmin Fluri with “The Science of Database CI/CD”. I already had the long form of this presentation because I read Jasmin’s masters thesis, but I was interested to see how she summarised some of it into a presentation. She did a great job of getting the main points into a 45 minute session, which can’t have been easy. It was also a little depressing, because I’ve come a long way , but I’ve still got such a long way to go. Ah well…
After Jasmin was Erik van Roon with “Scripting in SQLcl – You Can Never Have Enough of a Good Thing”. The session discussed how to extend the functionality of SQLcl with your own commands written in JavaScript. I get the distinct impression Erik has too much time on his hands. If anyone wants to join me in staging an intervention, just let me know. 🙂 I’m not sure if I will use this functionality, but it’s always good to know it exists, because you never know when it might come in handy, and knowing it’s possible is the first step.
Last up for me was “The Death of the Data Scientist, But Long Live Data Science” by Brendan Tierney. To summarise Brendan talked about the recent mass layoffs of data scientists, suggesting a number of factors including a glut of data scientists on the market, low return on investment from many data science teams, and the simplification and automation of data science to the point where it had now been integrated into products and domain-specific staff roles. It’s typical hype cycle stuff. We’ve moved from the “Peak of Inflated Expectations” to the “Trough of Disillusionment”, and the job market has corrected itself because of that. It doesn’t sound like a move from DBA to data scientist is a great career move right now. 🙂
I spent some time chatting to Brendan, then it was off to beat the traffic home so I could return to real life again.
UKOUG Breakthrough 2022 is over now, and it was a good introduction back into the world of face to face conferences for me. I’m still very nervous about the thought of travelling, but based on the last few days I’m hoping I can get my conference mojo back. Just don’t expect too much too soon. 🙂
Thanks to all the conference organisers and speakers for giving up their time to make this happen. See you all again soon.
Why do I do this? As mentioned in the first link, Fedora is a proving ground for future versions of RHEL, and therefore Oracle Linux. I like to see what is coming around the corner. Doing this has no “real world” value, but I’m a geek, and this is what geeks do.
Having recently put out a post about database patching, I was interested to know what people out in the world were doing, so I went to Twitter to ask.
As always, the sample size is small and my followers have an Oracle bias, so you can decide how representative you think these number are…
Patching Frequency
Here was the first question.
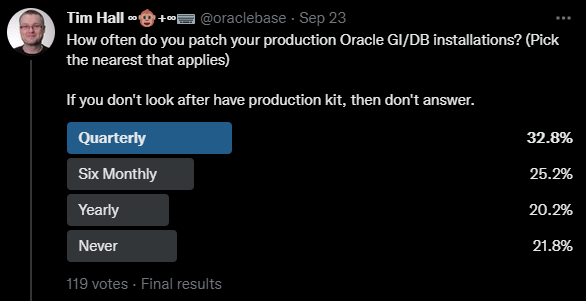
How often do you patch your production Oracle GI/DB installations? (Pick the nearest that applies)
There was a fairly even spread of answers, with about a third of people doing quarterly patching, and a quarter doing six-monthly patching. I feel like both these options are reasonable. About 20% were doing yearly patching, which is starting to sound a little risky to me. The real downer was over 22% of people never patch their databases. This is interesting when you consider the recent announcement about monthly recommended patches (MRPs).
For those people that never patch, I can think of a few reasons off the top off my head why.
Lack of testing resource. I think patch frequency has more to do with testing than any other factor. If you have a lot of databases, the testing resource to get through a patching cycle can be quite considerable. This is why you have to invest some time and money into automated testing.
If it ain’t broke, don’t fix it. The problem is, it is broken! How long after your system has been compromised will it be before you notice? How are your customers going to feel when you have a data breach and they find out you haven’t even taken basic steps to protect them? I don’t envy you explaining this…
Fear of downtime. I know downtime is a real issue to some companies, but there are several ways to mitigate this, and you have to balance the pros and the cons. I think if most people are honest, they can afford the downtime to patch their systems. They are just using this as an excuse.
Patching is risky. I understand that patches can introduce new issues, but that is why there are multiple ways to patch, with some being more conservative from a risk perspective. I think this is just another excuse.
Out of support database versions. I think this is a big factor. A lot of people run really old versions of the database that are no longer in support, and are no longer receiving patches. I don’t even think I need to explain why this is a terrible idea. Once again, how are you going to explain this to your customers?
Lack of skills. We like to think that every system is looked after by a qualified DBA, but the reality is that is just not true. I get a lot of questions from people who are SQL Server and MySQL DBAs that have been given some Oracle databases to look after, and they freely admit to not having the skills to look after them. Even amongst Oracle DBAs there is a massive variation in skills. Oracle patching has improved over the years, but it is still painful compared to other database engines. Just saying.
Type of Patching
This was the second question.
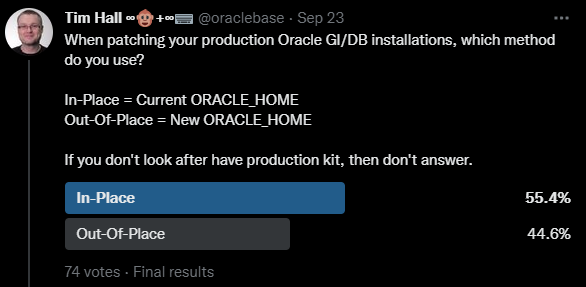
When patching your production Oracle GI/DB installations, which method do you use? In-Place = Current ORACLE_HOME Out-Of-Place = New ORACLE_HOME
This was a fairly even split, with In-Place winning by a small margin. Oracle recommend Out-Of-Place patching, but I think both options are fine if you understand the implications. I discussed these in my previous post.
Conclusion
I think of patch frequency in a similar way to upgrade frequency. If you do it very rarely, it’s really scary, and because nobody remembers what they did last time, there are a bunch of problems that occur, which makes everyone nervous about the next patch/upgrade. There are two ways to respond to this. The first is to delay patching and upgrades as long as possible, which will result in the next big disaster project. The second is to increase your patch/upgrade frequency, so everyone becomes well versed in what they have to do, and it becomes a well oiled machine. You get good at what you do frequently. As you might expect, I prefer the second option. I’ve fought long and hard to get my company into a quarterly patching schedule, and it will only decrease in frequency over my dead body!
Assuming the results of these polls are representative of the wider community, I feel like Oracle need to sit up and take notice. Patching is better than it was, but “less bad” is not the same as “good”. It is still too complicated, and too prone to introducing new issues IMHO!
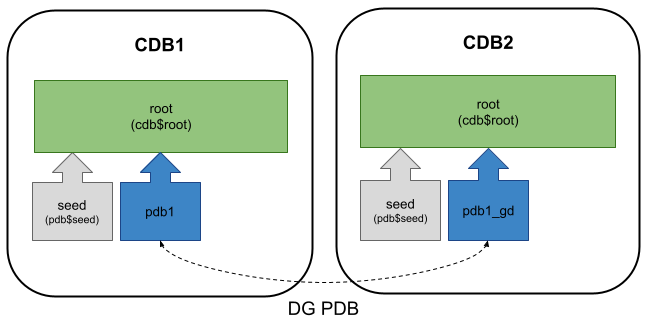
I also did a Vagrant build, which includes the build of the servers, the database software installations, database creations and the perquisites, so you can jump straight to the DG PDB configuration section in the article. You can find that build here.
So that’s the basic how-to covered, and I really do mean “basic”. There is a lot more people might want to do with it, but it’s beyond the scope of my little Vagrant build.
What do I think about it?
Well I guess you know how this is going to go, based on the title of this post. I don’t like it (yet), but I’m going to try and be a bit more constructive than that.
It is buggy! : I know 21c is an innovation release, but this is a HA/DR solution, so it needs to be bullet proof and it’s not. There are a number of issues when you come to use it, which will most likely be fixed in a future release update, or database version, but for now this is a production release and I don’t feel like it is safe pair of hands for real PDBs. That is a *very* bad look for a product of this type.
Is it Data Guard? Really? : Once again, I know this is the first release of this functionality, but there are so many restrictions associated with it that I wonder if it is even deserving of the Data Guard name. I feel like it should have been a little further along the development cycle before it got associated with the name Data Guard. The first time someone has a problem with DG PDB, and they definitely will, they are going to say some choice words about Data Guard. I know this because I was throwing around some expletives when I was having issues with it. That’s not a feeling you want to associated with one of your HA/DR products…
Is this even scriptable? : The “add pluggable database” step in the DGMGRL utility prompts for a password. Maybe I’ve missed something, but I didn’t see a way to supply this silently. If it needs human interaction it is not finished. If someone can explain to me what I’ve missed, that would be good. If I’m correct and this can’t be done silently, it needs some new arguments. It doesn’t help that it consistently fails the first time you call it, but works the second time. Ouch!
Is the standby PDB created or not? : When you run the “add pluggable database” command (and it eventually works) it creates the standby PDB, but there are no datafiles associated with it. You have to copy those across yourself. The default action should be to copy the files across. Oracle could do it quite easily with the DBMS_FILE_TRANSFER package, or some variant of a hot clone. There should still be an option to not do the datafile copy, as some people might want to move the files manually, and that is fine, but to not have a way to include the file copy seems a bit crappy.
Ease of use : Oracle 21c introduced the PREPARE FOR DATA GUARD command, which automates a whole bunch of prerequisites for Data Guard setup, which is a really nice touch. Of course DG PDB has many of the same prerequisites, so you can use PREPARE FOR DATA GUARD to get yourself in a good place to start, but I still feel like there are too many moving parts to get going. I really want it to be a single command that takes me from zero to hero. I could say this about many other Oracle features too, but that’s the subject of another blog post.
Overall : A few times I got myself into such a mess the only thing I could do was rebuild the whole environment. That’s not a good look for a HA/DR product!
Conclusion
I’m sorry if I’ve pissed off any of the folks that worked on this feature. It wasn’t my intention. I just don’t think this is ready to be included in a production release yet. I’m hoping I can sing its praises of a future release of this functionality!
I had a strop on Twitter again about My Oracle Support, and I just want to document why.
Someone on Twitter pointed out to me that the “active” real-time SQL monitoring reports weren’t working. It’s really easy to demonstrate, so I ran through it, and sure enough it was broken. When you opened the report in a browser, some of the dependent files (Javascript and a Flash movie) were missing, giving a 404 error.
I opened a service request (SR) on My Oracle Support (MOS). The first hurdle was the “Problem Type”. It’s mandatory, and the list of options is crap. Keep in mind that what you pick launches you into a load of automations, so picking the wrong thing is painful, but you typically have to because there is no “none of the above” option to pick… I decided on a performance related option, since the issue was a to do with the real-time SQL monitoring feature, even though I know this was not about the performance of my database…
I gave a link to a working example, and uploaded a generated report and the output from the Chrome developer console, showing all the 404 errors. It was a pretty self contained thing, so I was sure it would be understood as soon as a human saw it. This is what happened next…
An automated response.
Another automated response.
Another automated response.
Another automated response.
By now you can imagine I’m getting a little annoyed, so this is my response.
This was followed by a repost of my original post. Word for word. Seemed rather strange, but ok…
This was followed by three automated messages saying the same thing.
I was about to go supernova at this point, but I managed not to lose my shit.
Finally we have someone claiming to be a human!
I get asked to look at something that wasn’t directly related to the point of my SR.
I can feel the rage building.
The following day the person actually runs my report, which was uploaded in my initial SR opener, and it works for them. They update the SR. Once I see the update I try and sure enough it works for me now too. At some point between me opening the SR and this last interaction the “missing” files on http://download.oracle.com/otn_software/ have become available again. I tell them to close the SR.
Thoughts
Remember, this is about as simple an SR as you can get. I posted a test case to demonstrate it. It was really self-contained and simple. I don’t want to think what would happen with a “difficult” issue.
The “Problem Type” selection during SR creation is a problem. I understand MOS want to use it to help automate the gathering of information, but it needs a “none of the above” option, or you are *forced* to pick something you know is wrong.
The automated messages are terrible. I ranted about this before, which resulted in this post.
The messages that came out of that meeting were really positive, but it’s over 2.5 years later and if anything it’s got worse…
Someone from Oracle Support has reached out to me, so I have a call with them tomorrow. I’m not sure this call will result in any positive change. It feels a bit like groundhog day…
Overall, My Oracle Support (MOS) is a terrible user experience, and Oracle should not be charging this much money for this terrible service.
Cheers
Tim…
PS. It’s 2022. Why can’t people call me “Tim” rather than “Timothy”?
I’ve been thinking about my DBA and PL/SQL tool choices recently, so I thought I would go out to Twitter and ask the masses what they are using.
As always, the sample size is small and my followers have an Oracle bias, so you can decide how representative you think these number are…
Here was the first question.
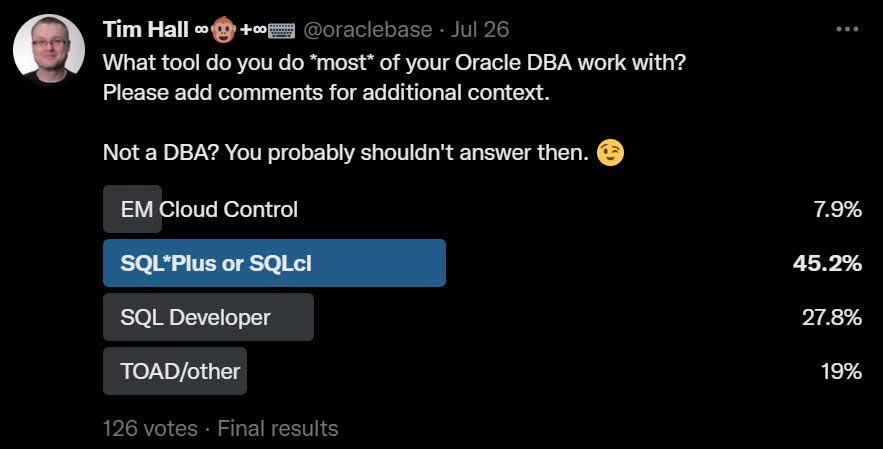
What tool do you do *most* of your Oracle DBA work with?
I expected SQL*Plus and SQLcl to be the winner here, and I was right. A lot of DBAs are still “old school” where administration is concerned. It may be tough for a beginner to use these command line tools, but over time you build up a list of scripts that mean it is much quicker than using GUI tools for most jobs.
SQL Developer had a pretty good showing at nearly 28%. I’m glad people are finding value in the DBA side of SQL Developer. TOAD/other were not doing so well. I know there are a lot of companies out there trying to make money with DBA tools, but maybe this is a tough market for them. Of course there are cross platform tools that may do well with other engines, even though they don’t register so well with the Oracle crowd.
I guess the real surprise was less than 8% using EM Cloud Control. Having said that, I’m considering ditching it myself. I like the performance pages and we use it as a centralized scheduler for backups, but I’m not sure our usage justifies the crazy bloat that is Cloud Control. It would be nice to remove all those agents and clean up! This figure of less than 8% is all the more surprising when you consider it is free (no cost option). Of course total cost of ownership is not just about the price tag…
This was the next question.
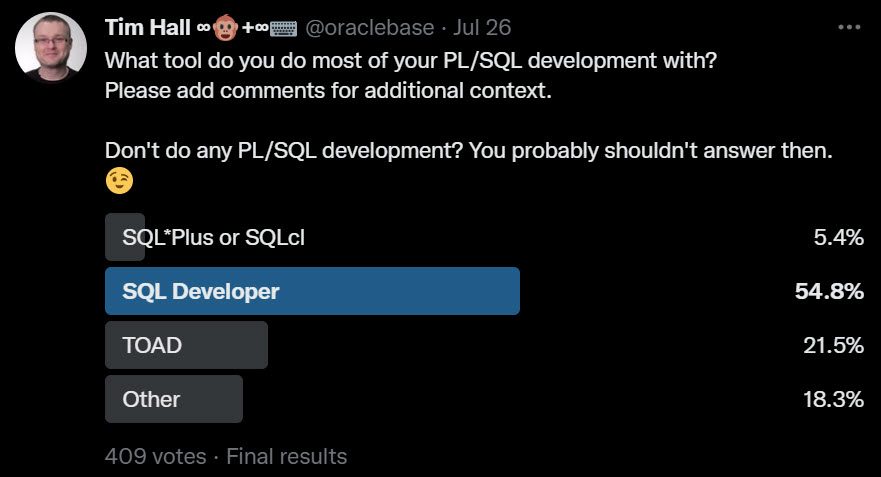
What tool do you do most of your PL/SQL development with?
I was expecting SQL Developer to do well here, but I was surprised by how low TOAD was in the list. I’ve worked at a few companies over the years where TOAD was a staple. I guess the consistent improvements to SQL Developer and a price tag of “free” have broken the TOAD strangle hold.
There were a few comments about Allround Aautomations PL/SQL Developer, which I used in one company many years ago. If I could have added an extra line in the poll, I would have put that as an option, because I know it is still popular. There were also mentions of DataGrip and a number of people using VS code with assorted extensions, including Oracle Developer Tools for VS Code.
Sadly, but understandably, SQL*Plus and SQLcl were low on this list. I’m an old timer, so I’ve had jobs where this was the only option. At one job I wrote my own editor in Visual Basic, then rewrote it in Java. Once SQL Developer (known as Raptor at the time) was released I stopped working on my editor…
When you’re doing “proper” PL/SQL development, it’s hard not to use an IDE. They just come with so much cool stuff to make you more productive. These days I tend to mostly write little utilities, or support other coders, so I find myself writing scripts in UltraEdit and compiling them in SQLcl. If I went back to hard core PL/SQL development, I would use an IDE though…
For fun I ended with this question.
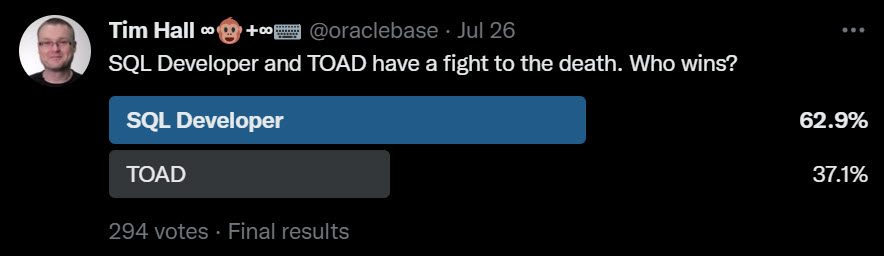
SQL Developer and TOAD have a fight to the death. Who wins?
SQL Developer won, but it came out with a detached retina and some broken ribs!
Remember, you are most productive using the tools that suit your working style, but you should always keep your eyes open for better ways of working. Choice is a wonderful thing!
The quarterly Oracle security patches trigger a whole bunch of build changes for me. This post just gives you a run through of what happened over the weekend.
Packer
The release of VirtualBox 6.1.36 means all my Vagrant boxes on Vagrant Cloud have the wrong guest additions, so I rebuilt all of them using Packer. The Oracle Linux 7, 8 and 9 boxes are now up to date. You can see my Packer builds under my Vagrant repository on GitHub here.
Note. During the packer builds I noticed the VirtualBox 6.1.36 guest additions require some extra packages during the installation (libX11, libXt, libXext, libXmu).
Vagrant
I had recently updated all relevant Vagrant builds with the latest versions of Tomcat, SQLcl and ORDS updates, but I was still waiting on the OpenJDK 11.0.16 release. On Friday morning I noticed Adoptium released it, so I made the necessary changes to the builds to include it. I usually don’t include Oracle patches in my database builds, but some installations, like Oracle 19c on OL8, require them. I’ve updated them to include the 19.16 patches where necessary. You can find my Vagrant builds on GitHub here.
Similar to the Vagrant section above, the relevant Docker/Podman builds were updated to use OpenJDK 11.0.16, and the Oracle 19c on OL8 build had it’s patch script modified for the 19.16 patches. You can find my container stuff on GitHub here.