I can’t explain how much I despise being forced to use a GUI to do something that could be scripted.
If you are a software vendor, please make sure you offer some form of scriptable API to interact with your product, and make sure it’s documented properly. I don’t care how much time and effort you put into your GUI, I don’t want to use it. I want everything in a script that can be checked into Git and automated.
If you are a software vendor that doesn’t provide a scriptable way to interact with your system, you are going to the bottom of my list. Even if I am forced to use your product now, I will switch at the first possible opportunity.
Staff
I’m sure this will ruffle a few feathers, but as I said in the linked article, when I see people using a GUI to perform certain maintenance operations my immediate reaction is they are wasting time. It is very rare a manual operation will be as fast and accurate as a scripted operation.
In the past we have hired “experts” to do work for us, and they’ve taken days working with GUIs to accomplish something that could have been scripted and run in much less time. If they are truly experts I would have expected them to have scripts for everything they do anyway.
I realise some consultants are running up chargeable hours by taking the long route, and some are not the experts they claim to be. It is noticed!
Why the rant?
The further down the rabbit hole I go with automation, the less I can stand doing manual operational work. I’m reaching the point where the mere sight of an unnecessary GUI gives me toxic shock…
GUIs have their place, but not for operational tasks IMHO!
After my previous post on using ChatGPT to write code, I just wanted to say a few words about using artificial intelligence (AI) to generate content such as articles and blog posts.
I’ll list a few specific issues and give my comments on them.
Using AI for inspiration
I watched a video by Marques Brownlee discussing the Bing integration of ChatGPT (here), and one of the things he mentioned was using AI for inspiration. Not expecting AI to create a whole piece of work for you, but using a chat with the AI to come up with ideas.
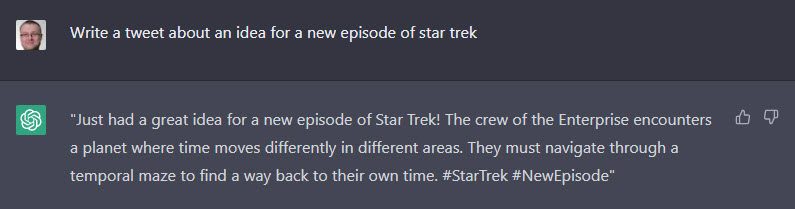
It reminded me of one of my first attempts at using ChatGPT, which was this. 🙂
Write a tweet about an idea for a new episode of star trek
If I were really trying to write something original, I might use this as the inspiration to create my own piece of work.
It should be noted, when I tweeted about this someone replied to say it was similar to the plot of a film they had seen, so we need to be careful the AI is not just stealing someone else’s idea. 🙂
I have no problem with people using AI as part of the generation of ideas. Just be careful that the ideas you get are vaguely original. 🙂
Turning bullet points into prose
One of my friends works for a company that ships physical products. The company has a paper catalogue, as well as an online store. He gets product details from the manufacturers and needs to pretty them up for use in their catalogue and website. He told me he is now using ChatGPT to do this.
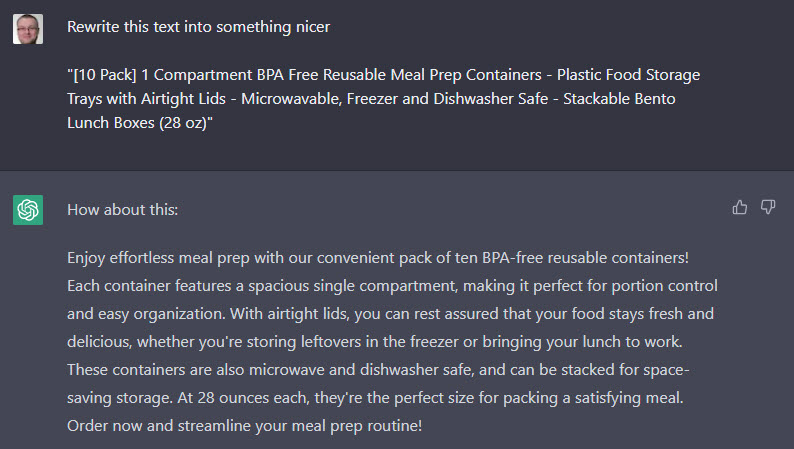
To give you an idea of what he is doing I copied some text of Amazon and asked ChatGPT to make it a bit nicer.
Rewrite this text into something nicer
In this case we aren’t expecting the AI to get facts from the internet. We are providing the base information and using the AI as a writing aid.
This is another use case I think it totally fine. It’s merely a tool that saves you a bit of time. People already use tools like Grammarly to help with spelling and grammar. This just seems like a logical next step to me.
It makes mistakes
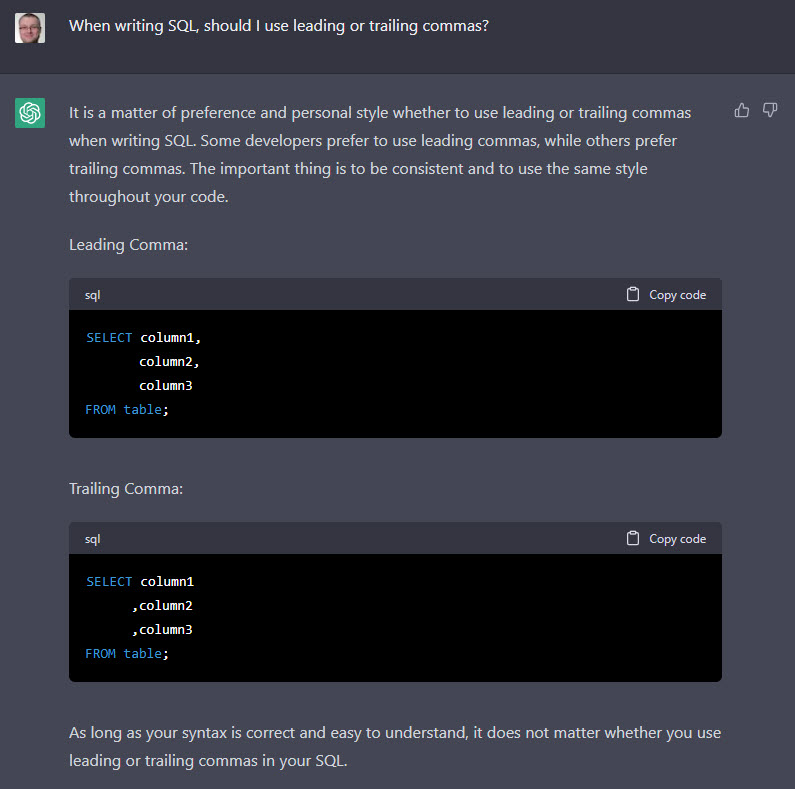
The AI doesn’t know anything about the content it is generating, so it can’t fact check itself. Here’s another example of something I Tweeted out. I asked ChatGPT if I should use leading or trailing commas when writing SQL.
When writing SQL, should I use leading or trailing commas?
It came back with a nice answer saying it is a personal preference, and gave an example of the two styles. The slight problem was the examples demonstrate the opposite of what they are meant to. 🙂
A human can pick that up, correct it and we will get something that seems reasonable, but it proves the point that we can’t blindly accept the output of AI content generation. We need to proof read and fact check it. This can be difficult if it doesn’t cite the sources used during the generation.
Sources and citations
Currently ChatGPT is based on a 2021 data set. When we use it we get no citations for the sources of information used during the generation process. This causes a number of problems.
It makes it hard to fact check the information.
It is impossible to properly cite the sources.
We can’t read the source material to check the AI’s interpretation is correct.
We can’t make a judgement on how much we trust the source material. Not all sources are reputable.
We can’t check to see if the AI has copied large pieces of text, leaving us open to copyright infringement. The generated text is supposedly unique, but can we be certain of that?
The Bing integration of ChatGPT does live searches of the internet, and includes citations for the information sources used, which solves many of these problems.
Copyright
AI content generation is still fairly new, but we are already seeing a number of issues related to copyright.
There are numerous stories about AI art generation infringing the copyright of artists, with many calling for their work to be opted out of the training data sets for AI, or to be paid for their inclusion. There is a line between inspiration and theft, and many believe AI art generation has crossed it. It’s possible this line has already been crossed in AI text generation also.
There is also the other side of copyright to consider. If you produce a piece of work using AI, it’s possible you can’t copyright that piece of work, since copyright applies to work created by a human. See the discussion here.
You can argue about the relative amounts of work performed by the AI and the human, but it seems that for 100% AI generation you are skating on thin ice. Of course, things can change as AI becomes more pervasive.
Who is paying for the source material to be created?
Like it or not, the internet is funded by ad revenue. Many people rely on views on their website to pay for their content creation. Anything that stops people actually visiting their site impacts on their income, and will ultimately see some people drop out of the content creation space.
When Google started including suggested answers in their Google search results, this already meant some people no longer needed to click on the source links. ChatGTP takes that one step further. If it becomes common place for people to search on Bing (or any other AI backed search engine), and use the AI generated result presented, rather than visiting the source sites, this will have a massive impact on the original content creators. The combination of this and ad blockers may mean the end for some content creators.
If there is no original content on the internet, there is nothing for AI to use as source material, and we could hit a brick wall. Of course there will always be content on the internet, but I think you can see where I’m going with this.
So just like the copyright infringement issues with AI art, are we going to see problems with the source material used for AI text generation? Will search engines have to start paying people for the source material they use? We’ve already seen this type of issue with search engines reporting news stories.
The morality of writing whole posts with AI
This is where things start to get a bit tricky, and this is more about morality and ethics, rather than content.
Let’s say your job is to write content. Someone is paying you to spend 40 hours a week writing that content, and instead you spend a few minutes generating content with AI, and use the rest of the time to watch Netflix. You can argue you are delivering what is asked of you and making intelligent use of automation, or that you are stealing from the company because you are being paid for a job you are not doing. I’m guessing different people will have a different take on this from a moral perspective.
Continuing with the theme of being paid to write, what if the company you are working for is expecting to have copyright control over the work you produce? If it can be determined it is AI generated, they can’t copyright it, and that work can be republished with no comeback. I can see that making you rather unpopular.
Education establishments already use software to check for plagiarism. The use of AI is already making educational establishments nervous. OpenAI, the creators of ChatGPT, have already created an AI Text Classifier (discontinued) to identify text that has been generated by AI. I can only imagine these types of utilities will become common place, and you could find yourself in hot water if you are passing off AI generated work as your own. You will certainly lose your qualifications for doing it.
Many people use their blogs as an indication of their expertise. They are presenting themselves as well versed in a subject, which can then lead to other opportunities, such as job offers, invitations to conferences and inclusion in technology evangelism programs. If it becomes apparent the content is not your own work, it would seem logical that your professional reputation would be trashed, and you would lose some or all of the benefits you have gained.
Conclusion
There is no right and wrong answer here, but in my opinion it’s important we use AI as a tool, and not a mechanism to cheat. Where we draw the line will depend on the individual, and the nature of the work being done. Also, it’s possible that line in the sand will change over time…
It’s an age old story. Your company wants to adopt some new tech stuff, but they set themselves up to fail. It doesn’t matter what we are talking about, it always happens because of one or more common traps.
Ignoring the learning curve
It takes time to become proficient at something new, but companies often don’t see this skilling up time as “productive”. They want to see results as soon as possible. This often means you will rush stuff out to production without a complete understanding of what you are doing, which then has one of several knock-on effects, most of which are negative.
I’m not suggesting you should wait until everyone is an expert, but there has to be some sensible effort to skill up before launching into production work. That’s typically not a one week course then go, and it’s also not a one week course, followed by a six month gap, then go.
Iterative development fails
In an attempt to counter the problem with the learning curve you try to work on an iterative basis. That way you can take stock at regular intervals, understand what is working and what is not, then go through a process of refactoring to bring everything in line with your new understanding. In the end you should get to the right place, but see the next section.
There is nothing wrong with iterative development itself. The problem comes from when it is applied badly. True of many things.
Refactoring is not productive work
Imagine the scenario.
You: In the process of doing the last couple of projects we’ve learned so much. Mostly how wrong we got things. We need to go through and refactor all the existing code to bring it into line with our current approach.
Company: What do we get out of this?
You: Well it will allow us to apply our current best practices and make the code more future proof and supportable.
Company: But will we get any new functionality? New screens? New shiny things?
You: No.
Company: So about these new top priorities we want you to work on. They are really shiny!
You: But what about the refactoring?
Company: Yeah, that’s not going to happen. Add it to the list of technical dept.
Because refactoring delivers nothing new in the eyes of many people in the business, it is considered really low priority. Despite the good intentions of iterative development, the amount of crap keeps piling up until you reach a breaking point. Unless you can schedule in time for internal projects to clean up technical dept, you are building up failures for the future.
We’ll get in some consultants to help us
One option is to get some people with the prerequisite experience to help you deliver the new tech. The idea being those people can hit the ground running, and start knowledge spreading to help your company adopt the new tech more quickly.
In theory this is a great idea, but how many times have you seen this fail? The consultants are hired to do the work, given deadlines that leave no time for knowledge spreading, and leave once their contract is up. At best you have a working product you can look at and use for inspiration, but often you are left with a half-baked solution you would like to scrap and rewrite yourself.
This is not a criticism of the consultants. Often it is a garbage in, garbage out situation. It takes time to learn the vocabulary to be able to discuss the issues properly, know what questions to ask, and communicate your requirements. For bleeding edge tech you might be paying someone to learn for you, with all the problems that entails.
Making everything match your existing company structure
Many companies have a company structure with siloed teams taking on specific roles. Each team acting as a gatekeeper for that specific part of the tech stack. On paper it seems to make the teams more efficient, see efficiency paradox, but in reality it results in endless amounts of lost time in hand-offs between teams, waiting for tickets to be processed. See Conway’s Law.
When you are trying something new, you have to consider that your existing team structures may not work well with that new tech. Trying to force it into your existing structure may cause it to fail, or at least not deliver the benefits you expected. This is one of the reasons why cloud, DevOps and automation have been so problematic for many companies, as they blur the lines between existing silos.
As I’ve mentioned in previous posts, silos aren’t totally evil. They can work just fine as long as they deliver value through services, allowing users to work in a self-service manner. The problems come when you are waiting on a ticket to be processed to get what you need.
You don’t really want to change
Unfortunately there are a lot of people that talk a good talk about change, but ultimately don’t really want to change. They will either knowingly sabotage projects, or unknowingly sabotage them through inaction.
The only way change can happen is if senior management understand the need for change, and push everyone in that direction. No amount of personal heroics can solve the problems of a company culture that won’t accept change. If your company has a problem, it is 100% the fault of senior leadership.
Conclusion
There are lots of reasons why new initiatives fail. Companies are quick to blame the failures on external factors, but rarely put themselves in the spotlight as being the cause of the failure. There is very little in technology that is universally good or bad. The devil is in the detail!
Yesterday I took a trip across town to Birmingham City University (BCU) to do a talk to the students. The talk was called “The changing role of the DBA”.
It’s been over 3 years since I’ve done a face-to-face presentation. I did some online presentations at the start of lockdown, but it’s been 2 years since I’ve done one of those. With that in mind, when I was asked to do this session at BCU my instinctive response was to say no, but I bit the bullet and said yes, and I’m glad I did.
As the name suggests, the session was about how the role of the DBA as changed over my 27 years of working with Oracle tech. I like to think the content was general enough to be applicable to most technology roles, not just the DBA role. I covered a number of topics including the increasing footprint of the kit we work with, the increased variety of technology used, automation, cloud, and the impact of cloud and automation on operational DBA tasks.
Once I finished the presentation we moved out of the room where I spent over an hour chatting to some of the students and answering questions. It was really good fun.
Thanks to the folks at BCU for inviting me to speak, and thanks to the students for coming to the session and hanging around to chat after it. You all made it a really easy introduction back to live presentations for me. 🙂
I’ve said some of this stuff before, but I want to bring it all into a slightly different context.
Good user experience is…
Good user experience is not about forcing me to follow your atomic implementation of a feature. What do I mean by this? Let’s take look at some examples of getting it right (IMHO) from Oracle.
An Oracle REST Data Services (ORDS) web service is made up of a module with one or more templates, each with one or more handlers. We could define our service by defining a module, template and a handler separately, because that’s how the underlying implementation of an ORDS web service works. It’s fine, but it’s a bit over the top if I just want a quick little web service based on a query. That’s why we have been given the DEFINE_SERVICE procedure, allowing us to do all that other stuff in a single call (see here). For simple services this is all you need.
The database scheduler is a complex beast. We can define loads of things like schedules, programs, arguments, jobs classes, windows and of course jobs. That’s fine, but 99% of the time we just want a simple job, and the CREATE_JOB procedure allows us create one in a single call (see here).
In both cases we can choose between doing things the long/verbose way, or use the “cheat code” and do stuff in a single call. This is exactly the sort of thing I like when I’m using a feature. I want to know the flexibility is there if I need it, but if 99% of my requirements don’t, I want the cheat code so I can do what I need to do and move on. This also makes the feature more accessible to new people…
Good user experience is not…
As I mentioned above, good user experience is not about forcing me to follow your atomic implementation of a feature. Someone should take a step back and ask what would “normal” users really like? The answer is probably giving them an option to zone out and get all the prerequisites and config done for them. It’s not making them spend a weekend trying to figure out how to enable a feature, then finding it doesn’t really work properly anyway…
I’m a generalist. I have to work with lots of different products. When I open the docs and I see a list of prerequisites, and then multiple commands to actually set stuff up my heart sinks. I want a “we’ll do everything for you” option. That might sound funny because of my history, and if companies did that it would make my website redundant, but I feel we need to progress. We’ve been doing this nuts & bolts crap for too long. If I can automate it, Oracle can automate it. If Oracle can automate it, why don’t they?
I don’t want to name and shame. I’ve made some positive comments about Oracle in the previous section, but you know there are a whole bunch of Oracle things I could use as examples of what not to do. Oracle aren’t alone here. It applies to lots of other companies too.
But Tim, I want to…
I can already hear people typing their responses about their need to be in control and their obsessive configuration disorder. Shut up. I don’t care. The chances are, if you are reading this post, you are probably one of the people that can cope with all this tech, but there are many people who can’t, or don’t want to.
Won’t someone think of the children customers
I am a customer. My company is a customer. I can think of two things my company refuse to pay for because the functionality in question is unsupportable if I’m not available. Those are features we need, but won’t buy because they are overly complex for normal people to do well.
Now you can argue that cloud services will solve all these issues, but cloud adoption varies between regions, and maybe people will not pick your cloud. My company are a perfect example of that. We’ve consolidated on Azure, and although we don’t run any Oracle databases there yet, if we run Oracle on the cloud, it will probably be on Azure.
If you heard someone say, “I used to get a punch in the face every day, but now it’s only once a week. Things are good!”, you would think they were crazy. Less bad is not the same as good. I often think companies bring out tools and utilities that are “less bad” than what they had before. Not actually “good”. If you have been in the trenches, “less bad” might feel “good”, but it’s not.
I realise this is another rant, but I think it’s a subject that is worth a rant. I use a wide variety of tech from a number of companies, and some of them get on my nerves at times, because it feels like user experience is an after thought. You can’t expect everyone to no-life the learning curve for your products. I’m just saying how I feel, and I’m pretty sure I’m not alone here!
Cheers
Tim…
PS. I’m playing a bit fast and loose with the term user experience in this post, but hopefully you get what I mean…
I was watching a Twitter thread develop, where people were discussing which of two pieces of technology were “the best”, and I found myself thinking of evolution and selection pressure. I’m going to speak in simple terms, so I apologise in advance to folks with an education in this stuff, who are irritated by my simplifications…
Selection Pressure
Organisms evolve because of selection pressure. There is something about their environment that makes certain changes advantageous. Take the case of the peppered moth. To cut a long story short, it was a pale moth. Being pale was good camouflage as the places it hung around were a similar colour, so predators found it hard to spot them. Any mutations that made a peppered moth darker, made it more likely to be spotted and eaten, so mutations that caused the darker moths were unlikely to get through to the next generation. If you get eaten, you are less likely to breed. So there was a selection pressure in favour of being a pale peppered moth. Then along came the industrial revolution, which covered trees and walls in soot. All of a sudden, being pale made it easy for predators to see you and reduced your chances of breeding. Any moths with a mutation causing a darker colour were at an advantage, were more likely to breed, and quickly the predominant colour of peppered moths in industrial regions changed. The selection pressure was now for darker peppered moths.
In contrast, alligators have remained relatively unchanged since before the extinction of the dinosaurs. Sizes vary, but they look pretty much the same. Why? They are already the perfect design for their lifestyle, so there is no selection pressure forcing a change. If some new mutation happens, but it doesn’t give an advantage that affects the alligators chances of breeding, it’s unlikely to spread through the population. The selection pressure is low for the new mutation.
So what’s this got to do with technology? I’m hoping that’s simple for you to see.
If you invent a really smart bit of technology, but it has no major advantages over the existing technology out there, it’s unlikely to obliterate its competitors. Even if there is a technical benefit, that benefit has to be sufficiently large to make people stand up and take notice.
When we look at the database market, relational databases are the alligators. They are really well suited for the role they play. Every time a new non-relational engine comes along, it’s easy to get excited and think of it as the RDBMS-killer, but they are typically targeting different problems. The biggest threat to a specific relational database at the moment is other relational databases…
Survival of the Fittest
When people read “survival of the fittest”, they often forget that “fittest” relates to ability to breed and pass on your genes. The male peacock has stupid tail feathers that slow it down and put it at a higher risk of predation, but the peahens are all about the crazy tail feathers, so the physical disadvantage of the crazy tail feathers is a breeding advantage. Effectively the “least fit” for survival becomes the “most fit” for breeding…
But what about the peacock’s tail feathers in technology? There are a number of factors that make a technology attractive apart from technical excellence, so it’s not always “the best” that wins. For example:
Brand : I guess this is the obvious one. Apple is a premium brand. People will often spend extra money for a technically worse product because of the attraction of a brand. There is a reason companies spend big money on advertising and promoting their brand.
Community Support : If a product has a vibrant community, where it’s easy to get answers and support, it will be more attractive than a product with bad support and a weak community. Why intentionally put yourself at a disadvantage?
Staffing : It doesn’t matter how good a product is, if you can’t get staff with those skills, it’s probably not a great idea to base your future on it. This can be a problem for new technologies, but it also goes for old technologies that are falling out of favour. I wouldn’t be starting a new project using COBOL, even if it were well suited to the task.
Cost : There is a reason Android phones have a bigger market share than iPhones. They are cheaper, and therefore more attainable. Cost should be judged on total cost of ownership (TCO), not just the headline price tag…
I know this post has rambled a lot, but coming back to my original point, when I hear someone arguing about technical merits of a product, I find myself wondering if that’s actually relevant at all. Maybe it’s only a small fraction of what really matters…
Cheers
Tim…
PS. The first picture is a crocodile, not an alligator. I know they are different, but I liked this picture… 🙂