8i | 9i | 10g | 11g | 12c | 13c | 18c | 19c | 21c | 23ai | Misc | PL/SQL | SQL | RAC | WebLogic | Linux
Bulk Binds (BULK COLLECT & FORALL) and Record Processing in Oracle
This article is an update of one written for Oracle 8i (Bulk Binds) which includes new features available in Oracle 9i Release 2 and beyond.
- Introduction
- BULK COLLECT
- FORALL
- SQL%BULK_ROWCOUNT
- SAVE EXCEPTIONS and SQL%BULK_EXCEPTION
- Bulk Binds and Triggers
- Updates
Related articles.
- FORALL Support for Sparse Collections (10gR1)
- PLS-00436 Restriction in FORALL Statements Removed (11gR1)
- APPEND_VALUES Hint (11gR2)
- Collections in Oracle PL/SQL
Introduction
Oracle uses two engines to process PL/SQL code. All procedural code is handled by the PL/SQL engine while all SQL is handled by the SQL statement executor, or SQL engine.
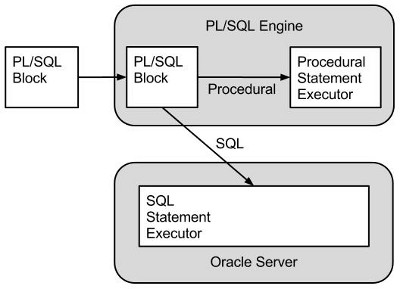
There is an overhead associated with each context switch between the two engines. If PL/SQL code loops through a collection performing the same DML operation for each item in the collection it is possible to reduce context switches by bulk binding the whole collection to the DML statement in one operation.
In Oracle8i a collection must be defined for every column bound to the DML which can make the code rather long winded. Oracle9i allows us to use Record structures during bulk operations so long as we don't reference individual columns of the collection. This restriction means that updates and deletes which have to reference inividual columns of the collection in the where clause are still restricted to the collection-per-column approach used in Oracle8i.
BULK COLLECT
Bulk binds can improve the performance when loading collections from a queries. The BULK COLLECT INTO construct
binds the output of the query to the collection. To test this create the following table.
CREATE TABLE bulk_collect_test AS
SELECT owner,
object_name,
object_id
FROM all_objects;
The following code compares the time taken to populate a collection manually and using a bulk bind.
SET SERVEROUTPUT ON
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF bulk_collect_test%ROWTYPE;
l_tab t_bulk_collect_test_tab := t_bulk_collect_test_tab();
l_start NUMBER;
BEGIN
-- Time a regular population.
l_start := DBMS_UTILITY.get_time;
FOR cur_rec IN (SELECT *
FROM bulk_collect_test)
LOOP
l_tab.extend;
l_tab(l_tab.last) := cur_rec;
END LOOP;
DBMS_OUTPUT.put_line('Regular (' || l_tab.count || ' rows): ' ||
(DBMS_UTILITY.get_time - l_start));
-- Time bulk population.
l_start := DBMS_UTILITY.get_time;
SELECT *
BULK COLLECT INTO l_tab
FROM bulk_collect_test;
DBMS_OUTPUT.put_line('Bulk (' || l_tab.count || ' rows): ' ||
(DBMS_UTILITY.get_time - l_start));
END;
/
Regular (42578 rows): 66
Bulk (42578 rows): 4
PL/SQL procedure successfully completed.
SQL>
We can see the improvement associated with bulk operations to reduce context switches.
The BULK COLLECT functionality works equally well for associative arrays (index-by tables), nested tables and varrays. In the case of associative arrays, the index will always be PLS_INTEGER and populated from 1 to N based on row order.
The select list must match the collections record definition exactly for this to be successful.
Remember that collections are held in memory, so doing a bulk collect from a large query could cause a considerable performance problem. In actual fact you would rarely do a straight bulk collect in this manner. Instead you would limit the rows returned using the LIMIT clause and move through the data processing smaller chunks. This gives you the benefits of bulk binds, without hogging all the server memory. The following code shows how to chunk through the data in a large table.
SET SERVEROUTPUT ON
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF bulk_collect_test%ROWTYPE;
l_tab t_bulk_collect_test_tab;
CURSOR c_data IS
SELECT *
FROM bulk_collect_test;
BEGIN
OPEN c_data;
LOOP
FETCH c_data
BULK COLLECT INTO l_tab LIMIT 10000;
EXIT WHEN l_tab.count = 0;
-- Process contents of collection here.
DBMS_OUTPUT.put_line(l_tab.count || ' rows');
END LOOP;
CLOSE c_data;
END;
/
10000 rows
10000 rows
10000 rows
10000 rows
2578 rows
PL/SQL procedure successfully completed.
SQL>
So we can see that with a LIMIT 10000 we were able to break the data into chunks of 10,000 rows, reducing the memory footprint of our application, while still taking advantage of bulk binds. The array size you pick will depend on the width of the rows you are returning and the amount of memory you are happy to use.
From Oracle 10g onward, the optimizing PL/SQL compiler converts cursor FOR LOOPs into BULK COLLECTs with an array size of 100. The following example compares the speed of a regular cursor FOR LOOP with BULK COLLECTs using varying array sizes.
SET SERVEROUTPUT ON
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF bulk_collect_test%ROWTYPE;
l_tab t_bulk_collect_test_tab;
CURSOR c_data IS
SELECT *
FROM bulk_collect_test;
l_start NUMBER;
BEGIN
-- Time a regular cursor for loop.
l_start := DBMS_UTILITY.get_time;
FOR cur_rec IN (SELECT *
FROM bulk_collect_test)
LOOP
NULL;
END LOOP;
DBMS_OUTPUT.put_line('Regular : ' ||
(DBMS_UTILITY.get_time - l_start));
-- Time bulk with LIMIT 10.
l_start := DBMS_UTILITY.get_time;
OPEN c_data;
LOOP
FETCH c_data
BULK COLLECT INTO l_tab LIMIT 10;
EXIT WHEN l_tab.count = 0;
END LOOP;
CLOSE c_data;
DBMS_OUTPUT.put_line('LIMIT 10 : ' ||
(DBMS_UTILITY.get_time - l_start));
-- Time bulk with LIMIT 100.
l_start := DBMS_UTILITY.get_time;
OPEN c_data;
LOOP
FETCH c_data
BULK COLLECT INTO l_tab LIMIT 100;
EXIT WHEN l_tab.count = 0;
END LOOP;
CLOSE c_data;
DBMS_OUTPUT.put_line('LIMIT 100: ' ||
(DBMS_UTILITY.get_time - l_start));
-- Time bulk with LIMIT 1000.
l_start := DBMS_UTILITY.get_time;
OPEN c_data;
LOOP
FETCH c_data
BULK COLLECT INTO l_tab LIMIT 1000;
EXIT WHEN l_tab.count = 0;
END LOOP;
CLOSE c_data;
DBMS_OUTPUT.put_line('LIMIT 1000: ' ||
(DBMS_UTILITY.get_time - l_start));
END;
/
Regular : 18
LIMIT 10 : 80
LIMIT 100: 15
LIMIT 1000: 10
PL/SQL procedure successfully completed.
SQL>
You can see from this example the performance of a regular FOR LOOP is comparable to a BULK COLLECT using an array size of 100. Does this mean you can forget about BULK COLLECT in 10g onward? In my opinion no. I think it makes sense to have control of the array size. If you have very small rows, you might want to increase the array size substantially. If you have very wide rows, 100 may be too large an array size.
FORALL
The FORALL syntax allows us to bind the contents of a collection to a single DML statement, allowing the DML to be run for each row in the collection without requiring a context switch each time. To test bulk binds using records we first create a test table.
CREATE TABLE forall_test ( id NUMBER(10), code VARCHAR2(10), description VARCHAR2(50)); ALTER TABLE forall_test ADD ( CONSTRAINT forall_test_pk PRIMARY KEY (id)); ALTER TABLE forall_test ADD ( CONSTRAINT forall_test_uk UNIQUE (code));
The following test compares the time taken to insert 10,000 rows using regular FOR..LOOP and a bulk bind.
SET SERVEROUTPUT ON
DECLARE
TYPE t_forall_test_tab IS TABLE OF forall_test%ROWTYPE;
l_tab t_forall_test_tab := t_forall_test_tab();
l_start NUMBER;
l_size NUMBER := 10000;
BEGIN
-- Populate collection.
FOR i IN 1 .. l_size LOOP
l_tab.extend;
l_tab(l_tab.last).id := i;
l_tab(l_tab.last).code := TO_CHAR(i);
l_tab(l_tab.last).description := 'Description: ' || TO_CHAR(i);
END LOOP;
EXECUTE IMMEDIATE 'TRUNCATE TABLE forall_test';
-- Time regular inserts.
l_start := DBMS_UTILITY.get_time;
FOR i IN l_tab.first .. l_tab.last LOOP
INSERT INTO forall_test (id, code, description)
VALUES (l_tab(i).id, l_tab(i).code, l_tab(i).description);
END LOOP;
DBMS_OUTPUT.put_line('Normal Inserts: ' ||
(DBMS_UTILITY.get_time - l_start));
EXECUTE IMMEDIATE 'TRUNCATE TABLE forall_test';
-- Time bulk inserts.
l_start := DBMS_UTILITY.get_time;
FORALL i IN l_tab.first .. l_tab.last
INSERT INTO forall_test VALUES l_tab(i);
DBMS_OUTPUT.put_line('Bulk Inserts : ' ||
(DBMS_UTILITY.get_time - l_start));
COMMIT;
END;
/
Normal Inserts: 305
Bulk Inserts : 14
PL/SQL procedure successfully completed.
SQL>
The output clearly demonstrates the performance improvements you can expect to see when using bulk binds to remove the context switches between the SQL and PL/SQL engines.
Since no columns are specified in the insert statement the record structure of the collection must match the table exactly.
Oracle9i Release 2 also allows updates using record definitions by using the ROW keyword. The following example uses the ROW keyword, when doing a comparison of normal and bulk updates.
SET SERVEROUTPUT ON
DECLARE
TYPE t_id_tab IS TABLE OF forall_test.id%TYPE;
TYPE t_forall_test_tab IS TABLE OF forall_test%ROWTYPE;
l_id_tab t_id_tab := t_id_tab();
l_tab t_forall_test_tab := t_forall_test_tab ();
l_start NUMBER;
l_size NUMBER := 10000;
BEGIN
-- Populate collections.
FOR i IN 1 .. l_size LOOP
l_id_tab.extend;
l_tab.extend;
l_id_tab(l_id_tab.last) := i;
l_tab(l_tab.last).id := i;
l_tab(l_tab.last).code := TO_CHAR(i);
l_tab(l_tab.last).description := 'Description: ' || TO_CHAR(i);
END LOOP;
-- Time regular updates.
l_start := DBMS_UTILITY.get_time;
FOR i IN l_tab.first .. l_tab.last LOOP
UPDATE forall_test
SET ROW = l_tab(i)
WHERE id = l_tab(i).id;
END LOOP;
DBMS_OUTPUT.put_line('Normal Updates : ' ||
(DBMS_UTILITY.get_time - l_start));
l_start := DBMS_UTILITY.get_time;
-- Time bulk updates.
FORALL i IN l_tab.first .. l_tab.last
UPDATE forall_test
SET ROW = l_tab(i)
WHERE id = l_id_tab(i);
DBMS_OUTPUT.put_line('Bulk Updates : ' ||
(DBMS_UTILITY.get_time - l_start));
COMMIT;
END;
/
Normal Updates : 235
Bulk Updates : 20
PL/SQL procedure successfully completed.
SQL>
The reference to the ID column within the WHERE clause of the first update would cause the bulk operation to fail, so the second update uses a separate collection for the ID column. This restriction has been lifted in Oracle 11g, as documented here.
Once again, the output shows the performance improvements you can expect to see when using bulk binds.
SQL%BULK_ROWCOUNT
The SQL%BULK_ROWCOUNT cursor attribute gives granular information about the rows affected by each iteration of the FORALL statement. Every row in the driving collection has a corresponding row in the SQL%BULK_ROWCOUNT cursor attribute.
The following code creates a test table as a copy of the ALL_USERS view. It then attempts to delete 5 rows from the table based on the contents of a collection. It then loops through the SQL%BULK_ROWCOUNT cursor attribute looking at the number of rows affected by each delete.
CREATE TABLE bulk_rowcount_test AS
SELECT *
FROM all_users;
SET SERVEROUTPUT ON
DECLARE
TYPE t_array_tab IS TABLE OF VARCHAR2(30);
l_array t_array_tab := t_array_tab('SCOTT', 'SYS',
'SYSTEM', 'DBSNMP', 'BANANA');
BEGIN
-- Perform bulk delete operation.
FORALL i IN l_array.first .. l_array.last
DELETE FROM bulk_rowcount_test
WHERE username = l_array(i);
-- Report affected rows.
FOR i IN l_array.first .. l_array.last LOOP
DBMS_OUTPUT.put_line('Element: ' || RPAD(l_array(i), 15, ' ') ||
' Rows affected: ' || SQL%BULK_ROWCOUNT(i));
END LOOP;
END;
/
Element: SCOTT Rows affected: 1
Element: SYS Rows affected: 1
Element: SYSTEM Rows affected: 1
Element: DBSNMP Rows affected: 1
Element: BANANA Rows affected: 0
PL/SQL procedure successfully completed.
SQL>
So we can see that no rows were deleted when we performed a delete for the username "BANANA".
SAVE EXCEPTIONS and SQL%BULK_EXCEPTION
We saw how the FORALL syntax allows us to perform bulk DML operations, but what happens if one of those individual operations results in an exception? If there is no exception handler, all the work done by the current bulk operation is rolled back. If there is an exception handler, the work done prior to the exception is kept, but no more processing is done. Neither of these situations is very satisfactory, so instead we should use the SAVE EXCEPTIONS clause to capture the exceptions and allow us to continue past them. We can subsequently look at the exceptions by referencing the SQL%BULK_EXCEPTION cursor attribute. To see this in action create the following table.
CREATE TABLE exception_test ( id NUMBER(10) NOT NULL );
The following code creates a collection with 100 rows, but sets the value of rows 50 and 51 to NULL. Since the above table does not allow nulls, these rows will result in an exception. The SAVE EXCEPTIONS clause allows the bulk operation to continue past any exceptions, but if any exceptions were raised in the whole operation, it will jump to the exception handler once the operation is complete. In this case, the exception handler just loops through the SQL%BULK_EXCEPTION cursor attribute to see what errors occured.
SET SERVEROUTPUT ON
DECLARE
TYPE t_tab IS TABLE OF exception_test%ROWTYPE;
l_tab t_tab := t_tab();
l_error_count NUMBER;
ex_dml_errors EXCEPTION;
PRAGMA EXCEPTION_INIT(ex_dml_errors, -24381);
BEGIN
-- Fill the collection.
FOR i IN 1 .. 100 LOOP
l_tab.extend;
l_tab(l_tab.last).id := i;
END LOOP;
-- Cause a failure.
l_tab(50).id := NULL;
l_tab(51).id := NULL;
EXECUTE IMMEDIATE 'TRUNCATE TABLE exception_test';
-- Perform a bulk operation.
BEGIN
FORALL i IN l_tab.first .. l_tab.last SAVE EXCEPTIONS
INSERT INTO exception_test
VALUES l_tab(i);
EXCEPTION
WHEN ex_dml_errors THEN
l_error_count := SQL%BULK_EXCEPTIONS.count;
DBMS_OUTPUT.put_line('Number of failures: ' || l_error_count);
FOR i IN 1 .. l_error_count LOOP
DBMS_OUTPUT.put_line('Error: ' || i ||
' Array Index: ' || SQL%BULK_EXCEPTIONS(i).error_index ||
' Message: ' || SQLERRM(-SQL%BULK_EXCEPTIONS(i).ERROR_CODE));
END LOOP;
END;
END;
/
Number of failures: 2
Error: 1 Array Index: 50 Message: ORA-01400: cannot insert NULL into ()
Error: 2 Array Index: 51 Message: ORA-01400: cannot insert NULL into ()
PL/SQL procedure successfully completed.
SQL>
As expected the errors were trapped. If we query the table we can see that 98 rows were inserted correctly.
SELECT COUNT(*) FROM exception_test; COUNT(*) ---------- 98 1 row selected. SQL>
Bulk Binds and Triggers
For bulk updates and deletes the timing points remain unchanged. Each row in the collection triggers a before statement, before row, after row and after statement timing point. For bulk inserts, the statement level triggers only fire at the start and the end of the the whole bulk operation, rather than for each row of the collection. This can cause some confusion if you are relying on the timing points from row-by-row processing.
You can see an example of this here.
Updates
- In Oracle 10g and above, the optimizing PL/SQL compiler rewrites conventional cursor for loops to use a
BULK COLLECTwith aLIMIT 100, so code that previously didn't take advantage of bulk binds may now run faster. - Oracle 10g introduced support for handling sparse collections in
FORALLstatements (here). - The restriction on accessing individual columns of the collection with a
FORALLhas been removed in Oracle 11g (here).
For more information see:
- Bulk Binds (8i)
- FORALL Support for Sparse Collections (10gR1)
- PLS-00436 Restriction in FORALL Statements Removed (11gR1)
- APPEND_VALUES Hint (11gR2)
- Collections in Oracle PL/SQL
- PL/SQL User's Guide and Reference Release 2 (9.2)
- Overview of Bulk Binds
Hope this helps. Regards Tim...