8i | 9i | 10g | 11g | 12c | 13c | 18c | 19c | 21c | 23ai | Misc | PL/SQL | SQL | RAC | WebLogic | Linux
Introduction to PL/SQL
PL/SQL is a procedural extension of SQL, making it extremely simple to write procedural code that includes SQL as if it were a single language. This article gives a brief overview of some of the important points you should consider when first trying to learn PL/SQL.
- What is so great about PL/SQL anyway?
- PL/SQL Architecture
- Overview of PL/SQL Elements
- My Utopian Development Environment
Related articles.
What is so great about PL/SQL anyway?
PL/SQL is a procedural extension of SQL, making it extremely simple to write procedural code that includes SQL as if it were a single language. In comparison, most other programming languages require mapping data types, preparing statements and processing result sets, all of which require knowledge of specific APIs.
The data types in PL/SQL are a super-set of those in the database, so you rarely need to perform data type conversions when using PL/SQL. Ask your average Java or .NET programmer how they find handling date values coming from a database. They can only wish for the simplicity of PL/SQL.
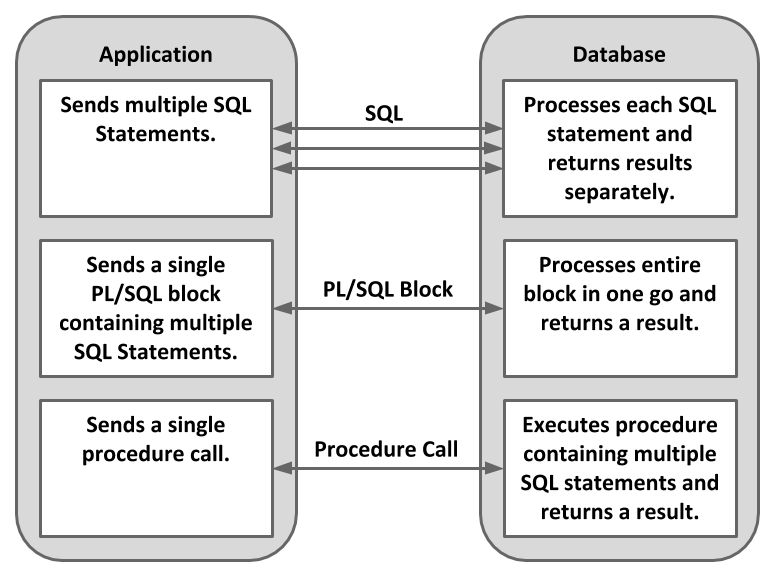
When coding business logic in middle tier applications, a single business transaction may be made up of multiple interactions between the application server and the database. This adds a significant overhead associated with network traffic. In comparison, building all the business logic as PL/SQL in the database means client code needs only a single database call per transaction, reducing the network overhead significantly.
Oracle is a multi-platform database, making PL/SQL and incredibly portable language. If your business logic is located in the database, you are protecting yourself from operating system lock-in.
Programming languages go in and out of fashion continually. Over the last 35+ years Oracle databases have remained part of the enterprise landscape. Suggesting that any language is a safer bet than PL/SQL is rather naive. Placing your business logic in the database makes changing your client layer much simpler if you like to follow fashion.
Centralizing application logic enables a higher degree of security and productivity. The use of Application Program Interfaces (APIs) can abstract complex data structures and security implementations from client application developers, leaving them free to do what they do best.
PL/SQL Architecture
The PL/SQL language is actually made up of two distinct languages. Procedural code is executed by the PL/SQL engine, while SQL is sent to the SQL statement executor.
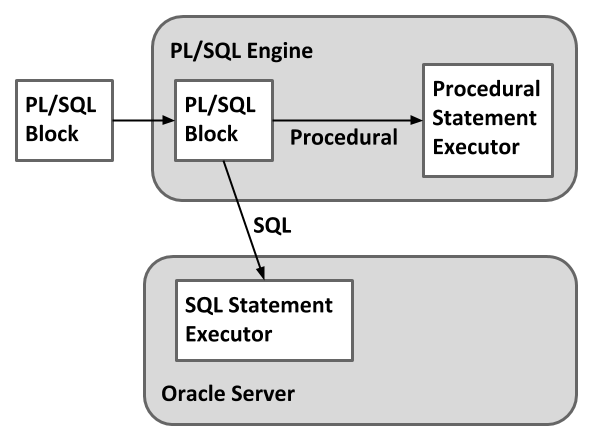
For the most part, the tight binding between these two languages make PL/SQL look like a single language to most developers.
Overview of PL/SQL Elements
Blocks
Blocks are the organizational unit for all PL/SQL code, whether it is in the form of an anonymous block, procedure, function, trigger or type. A PL/SQL block is made up of three sections (declaration, executable and exception), of which only the executable section is mandatory.
[DECLARE -- delarations] BEGIN -- statements [EXCEPTION -- handlers END;
Based on this definition, the simplest valid block is shown below, but it doesn't do anything.
BEGIN NULL; END;
The optional declaration section allows variables, types, procedures and functions do be defined for use within the block. The scope of these declarations is limited to the code within the block itself, or any nested blocks or procedure calls. The limited scope of variable declarations is shown by the following two examples. In the first, a variable is declared in the outer block and is referenced successfully in a nested block. In the second, a variable is declared in a nested block and referenced from the outer block, resulting in an error as the variable is out of scope.
DECLARE
l_number NUMBER;
BEGIN
l_number := 1;
BEGIN
l_number := 2;
END;
END;
/
PL/SQL procedure successfully completed.
BEGIN
DECLARE
l_number NUMBER;
BEGIN
l_number := 1;
END;
l_number := 2;
END;
/
l_number := 2;
*
ERROR at line 8:
ORA-06550: line 8, column 3:
PLS-00201: identifier 'L_NUMBER' must be declared
ORA-06550: line 8, column 3:
PL/SQL: Statement ignored
SQL>
The main work is done in the mandatory executable section of the block, while the optional exception section is where all error processing is placed. The following two examples demonstrate the usage of exception handlers for trapping error messages. In the first, there is no exception handler so a query returning no rows results in an error. In the second the same error is trapped by the exception handler, allowing the code to complete successfully.
DECLARE
l_date DATE;
BEGIN
SELECT SYSDATE
INTO l_date
FROM dual
WHERE 1=2; -- For zero rows
END;
/
DECLARE
*
ERROR at line 1:
ORA-01403: no data found
ORA-06512: at line 4
DECLARE
l_date DATE;
BEGIN
SELECT SYSDATE
INTO l_date
FROM dual
WHERE 1=2; -- For zero rows
EXCEPTION
WHEN NO_DATA_FOUND THEN
NULL;
END;
/
PL/SQL procedure successfully completed.
SQL>
Variables and Constants
Variables and constants must be declared for use in procedural and SQL code, although the datatypes available in SQL are only a subset of those available in PL/SQL. All variables and constants must be declared before they are referenced. The declarations of variables and constants are similar, but constant definitions must contain the CONSTANT keyword and must be assigned a value as part of the definition. Subsequent attempts to assign a value to a constant will result in an error. The following example shows some basic variable and constant definitions, along with a subsequent assignment of a value to a constant resulting in an error.
DECLARE l_string VARCHAR2(20); l_number NUMBER(10); l_con_string CONSTANT VARCHAR2(20) := 'This is a constant.'; BEGIN l_string := 'Variable'; l_number := 1; l_con_string := 'This will fail'; END; / l_con_string := 'This will fail'; * ERROR at line 10: ORA-06550: line 10, column 3: PLS-00363: expression 'L_CON_STRING' cannot be used as an assignment target ORA-06550: line 10, column 3: PL/SQL: Statement ignored SQL>
In addition to standard variable declarations used within SQL, PL/SQL allows variable datatypes to match the datatypes of existing columns, rows or cursors using the %TYPE and %ROWTYPE qualifiers, making code maintenance much easier. The following code shows each of these definitions in practice.
DECLARE
-- Specific column from table.
l_username all_users.username%TYPE;
-- Whole record from table.
l_all_users_row all_users%ROWTYPE;
CURSOR c_user_data IS
SELECT username,
created
FROM all_users
WHERE username = 'SYS';
-- Record that matches cursor definition.
l_all_users_cursor_row c_user_data%ROWTYPE;
BEGIN
-- Specific column from table.
SELECT username
INTO l_username
FROM all_users
WHERE username = 'SYS';
DBMS_OUTPUT.put_line('l_username=' || l_username);
-- Whole record from table.
SELECT *
INTO l_all_users_row
FROM all_users
WHERE username = 'SYS';
DBMS_OUTPUT.put_line('l_all_users_row.username=' ||
l_all_users_row.username);
DBMS_OUTPUT.put_line('l_all_users_row.user_id=' ||
l_all_users_row.user_id);
DBMS_OUTPUT.put_line('l_all_users_row.created=' ||
l_all_users_row.created);
-- Record that matches cursor definition.
OPEN c_user_data;
FETCH c_user_data
INTO l_all_users_cursor_row;
CLOSE c_user_data;
DBMS_OUTPUT.put_line('l_all_users_cursor_row.username=' ||
l_all_users_cursor_row.username);
DBMS_OUTPUT.put_line('l_all_users_cursor_row.created=' ||
l_all_users_cursor_row.created);
END;
/
l_username=SYS
l_all_users_row.username=SYS
l_all_users_row.user_id=0
l_all_users_row.created=18-MAR-2004 08:02:17
l_all_users_cursor_row.username=SYS
l_all_users_cursor_row.created=18-MAR-2004 08:02:17
PL/SQL procedure successfully completed.
SQL>
The %TYPE qualifier signifies that the variable datatype should match that of the specified table column, while the %ROWTYPE qualifier signifies that the variable datatype should be a record structure that matches the specified table or cursor structure. Notice that the record structures use the dot notation (variable.column) to reference the individual column data within the record structure.
Values can be assigned to variables directly using the ":=" assignment operator, via a SELECT ... INTO statement or when used as OUT or IN OUT parameter from a procedure. All three assignment methods are shown in the example below.
DECLARE
l_number NUMBER;
PROCEDURE add(p1 IN NUMBER,
p2 IN NUMBER,
p3 OUT NUMBER) AS
BEGIN
p3 := p1 + p2;
END;
BEGIN
-- Direct assignment.
l_number := 1;
-- Assignment via a select.
SELECT 1
INTO l_number
FROM dual;
-- Assignment via a procedure parameter.
add(1, 2, l_number);
END;
/
Using SQL in PL/SQL
The SQL language is fully integrated into PL/SQL, so much so that they are often mistaken as being a single language by newcomers. It is possible to manuallly code the retrieval of data using explicit cursors, or let Oracle do the hard work and use implicit cursors. Examples of both explicit implicit cursors are presented below, all of which rely on the following table definition table.
CREATE TABLE sql_test ( id NUMBER(10), description VARCHAR2(10) ); INSERT INTO sql_test (id, description) VALUES (1, 'One'); INSERT INTO sql_test (id, description) VALUES (2, 'Two'); INSERT INTO sql_test (id, description) VALUES (3, 'Three'); COMMIT;
The SELECT ... INTO statement allows data from one or more columns of a specific row to be retrieved into variables or record structures using an implicit cursor.
SET SERVEROUTPUT ON
DECLARE
l_description VARCHAR2(10);
BEGIN
SELECT description
INTO l_description
FROM sql_test
WHERE id = 1;
DBMS_OUTPUT.put_line('l_description=' || l_description);
END;
/
l_description=One
PL/SQL procedure successfully completed.
SQL>
The previous example can be recoded to use an explicit cursor a shown below. Notice that the cursor is now defined in the declaration section and is explicitly opened and closed, making the code larger and a little ugly.
SET SERVEROUTPUT ON
DECLARE
l_description VARCHAR2(10);
CURSOR c_data (p_id IN NUMBER) IS
SELECT description
FROM sql_test
WHERE id = p_id;
BEGIN
OPEN c_data (p_id => 1);
FETCH c_data
INTO l_description;
CLOSE c_data;
DBMS_OUTPUT.put_line('l_description=' || l_description);
END;
/
l_description=One
PL/SQL procedure successfully completed.
SQL>
When a query returns multiple rows is can be processed within a loop. The following example uses a cursor FOR-LOOP to cycle through multiple rows of an implicit cursor. Notice there is no need for a variable definition as "cur_rec" acts as a pointer to the current record of the cursor.
SET SERVEROUTPUT ON
BEGIN
FOR cur_rec IN (SELECT description
FROM sql_test)
LOOP
DBMS_OUTPUT.put_line('cur_rec.description=' || cur_rec.description);
END LOOP;
END;
/
cur_rec.description=One
cur_rec.description=Two
cur_rec.description=Three
PL/SQL procedure successfully completed.
SQL>
The explicit cursor version of the previous example is displayed below. Once again the cursor management is all done manually, but this time the exit from the loop must be managed manually also.
SET SERVEROUTPUT ON
DECLARE
l_description VARCHAR2(10);
CURSOR c_data IS
SELECT description
FROM sql_test;
BEGIN
OPEN c_data;
LOOP
FETCH c_data
INTO l_description;
EXIT WHEN c_data%NOTFOUND;
DBMS_OUTPUT.put_line('l_description=' || l_description);
END LOOP;
CLOSE c_data;
END;
/
l_description=One
l_description=Two
l_description=Three
PL/SQL procedure successfully completed.
SQL>
In most situations the implicit cursors provide a faster and cleaner solution to data retrieval than their explicit equivalents.
Branching and Conditional Control
The IF-THEN-ELSE and CASE statements allow code to decide on the correct course of action for the current circumstances. In the following example the IF-THEN-ELSE statement is used to decide if today is a weekend day.
SET SERVEROUTPUT ON
DECLARE
l_day VARCHAR2(10);
BEGIN
l_day := TRIM(TO_CHAR(SYSDATE, 'DAY'));
IF l_day IN ('SATURDAY', 'SUNDAY') THEN
DBMS_OUTPUT.put_line('It''s the weekend!');
ELSE
DBMS_OUTPUT.put_line('It''s not the weekend yet!');
END IF;
END;
/
First, the expression between the IF and the THEN is evaluated. If that expression equates to TRUE the code between the THEN and the ELSE is performed. If the expression equates to FALSE the code between the ELSE and the END IF is performed. The IF-THEN-ELSE statement can be extended to cope with multiple decisions by using the ELSIF keyword. The example below uses this extended form to produce a different message for Saturday and Sunday.
SET SERVEROUTPUT ON
DECLARE
l_day VARCHAR2(10);
BEGIN
l_day := TRIM(TO_CHAR(SYSDATE, 'DAY'));
IF l_day = 'SATURDAY' THEN
DBMS_OUTPUT.put_line('The weekend has just started!');
ELSIF l_day = 'SUNDAY' THEN
DBMS_OUTPUT.put_line('The weekend is nearly over!');
ELSE
DBMS_OUTPUT.put_line('It''s not the weekend yet!');
END IF;
END;
/
SQL CASE expressions were introduced in the later releases of Oracle 8i, but Oracle 9i included support for CASE statements in PL/SQL for the first time. The CASE statement is the natural replacement for large IF-THEN-ELSIF-ELSE statements. The following code gives an example of a matched CASE statement.
SET SERVEROUTPUT ON
DECLARE
l_day VARCHAR2(10);
BEGIN
l_day := TRIM(TO_CHAR(SYSDATE, 'DAY'));
CASE l_day
WHEN 'SATURDAY' THEN
DBMS_OUTPUT.put_line('The weekend has just started!');
WHEN 'SUNDAY' THEN
DBMS_OUTPUT.put_line('The weekend is nearly over!');
ELSE
DBMS_OUTPUT.put_line('It''s not the weekend yet!');
END CASE;
END;
/
The WHEN clauses of a matched CASE statement simply state the value to be compared. If the value of the variable specified after the CASE keyword matches this comparison value the code after the THEN keyword is performed.
A searched CASE statement has a slightly different format, with each WHEN clause containing a full expression, as shown below.
SET SERVEROUTPUT ON
DECLARE
l_day VARCHAR2(10);
BEGIN
l_day := TRIM(TO_CHAR(SYSDATE, 'DAY'));
CASE
WHEN l_day = 'SATURDAY' THEN
DBMS_OUTPUT.put_line('The weekend has just started!');
WHEN l_day = 'SUNDAY' THEN
DBMS_OUTPUT.put_line('The weekend is nearly over!');
ELSE
DBMS_OUTPUT.put_line('It''s not the weekend yet!');
END CASE;
END;
/
Looping Statements
Loops allow sections of code to be processed multiple times. In its most basic form a loop consists of the LOOP and END LOOP statement, but this form is of little use as the loop will run forever.
BEGIN
LOOP
NULL;
END LOOP;
END;
/
Typically you would expect to define an end condition for the loop using the EXIT WHEN statement along with a Boolean expression. When the expression equates to true the loop stops. The example below uses this syntax to pint out numbers from 1 to 5.
SET SERVEROUTPUT ON
DECLARE
i NUMBER := 1;
BEGIN
LOOP
EXIT WHEN i > 5;
DBMS_OUTPUT.put_line(i);
i := i + 1;
END LOOP;
END;
/
The placement of the EXIT WHEN statement can affect the processing inside the loop. For example, placing it at the start of the loop means the code within the loop may be executed "0 to many" times, like a while-do loop in other language. Placing the EXIT WHEN at the end of the loop means the code within the loop may be executed "1 to many" times, like a do-while loop in other languages.
The FOR-LOOP statement allows code within the loop to be repeated a specified number of times based on the lower and upper bounds specified in the statement. The example below shows how the previous example could be recorded to use a FOR-LOOP statement.
SET SERVEROUTPUT ON
BEGIN
FOR i IN 1 .. 5 LOOP
DBMS_OUTPUT.put_line(i);
END LOOP;
END;
/
The WHILE-LOOP statement allows code within the loop to be repeated until a specified expression equates to TRUE. The following example shows how the previous examples can be re-coded to use a WHILE-LOOP statement.
SET SERVEROUTPUT ON
DECLARE
i NUMBER := 1;
BEGIN
WHILE i <= 5 LOOP
DBMS_OUTPUT.put_line(i);
i := i + 1;
END LOOP;
END;
/
In addition to these loops a special cursor FOR-LOOP is available as seen previously.
GOTO
The GOTO statement allows a program to branch unconditionally to a predefined label. The following example uses the GOTO statement to repeat the functionality of the examples in the previous section.
SET SERVEROUTPUT ON
DECLARE
i NUMBER := 1;
BEGIN
LOOP
IF i > 5 THEN
GOTO exit_from_loop;
END IF;
DBMS_OUTPUT.put_line(i);
i := i + 1;
END LOOP;
<< exit_from_loop >>
NULL;
END;
/
In this example the GOTO has been made conditional by surrounding it with an IF statement. When the GOTO is called the program execution immediately jumps to the appropriate label, defined using double-angled brackets.
Procedures, Functions and Packages
Procedures and functions allow code to be named and stored in the database, making code reuse simpler and more efficient. Procedures and functions still retain the block format, but the DECLARE keyword is replaced by PROCEDURE or FUNCTION definitions, which are similar except for the additional return type definition for a function. The following procedure displays numbers between upper and lower bounds defined by two parameters, then shows the output when it's run.
CREATE OR REPLACE PROCEDURE display_numbers (
p_lower IN NUMBER,
p_upper IN NUMBER)
AS
BEGIN
FOR i IN p_lower .. p_upper LOOP
DBMS_OUTPUT.put_line(i);
END LOOP;
END;
/
SET SERVEROUTPUT ON
EXECUTE display_numbers(2, 6);
2
3
4
5
6
PL/SQL procedure successfully completed.
SQL>
The following function returns the difference between upper and lower bounds defined by two parameters.
CREATE OR REPLACE FUNCTION difference (
p_lower IN NUMBER,
p_upper IN NUMBER)
RETURN NUMBER
AS
BEGIN
RETURN p_upper - p_lower;
END;
/
VARIABLE l_result NUMBER
BEGIN
:l_result := difference(2, 6);
END;
/
PL/SQL procedure successfully completed.
PRINT l_result
L_RESULT
----------
4
SQL>
Packages allow related code, along with supporting types, variables and cursors, to be grouped together. The package is made up of a specification that defines the external interface of the package, and a body that contains all the implementation code. The following code shows how the previous procedure and function could be grouped into a package.
CREATE OR REPLACE PACKAGE my_package AS
PROCEDURE display_numbers (
p_lower IN NUMBER,
p_upper IN NUMBER);
FUNCTION difference (
p_lower IN NUMBER,
p_upper IN NUMBER)
RETURN NUMBER;
END;
/
CREATE OR REPLACE PACKAGE BODY my_package AS
PROCEDURE display_numbers (
p_lower IN NUMBER,
p_upper IN NUMBER)
AS
BEGIN
FOR i IN p_lower .. p_upper LOOP
DBMS_OUTPUT.put_line(i);
END LOOP;
END;
FUNCTION difference (
p_lower IN NUMBER,
p_upper IN NUMBER)
RETURN NUMBER
AS
BEGIN
RETURN p_upper - p_lower;
END;
END;
/
Once the package specification and body are compiled they can be executed as before, provided the procedure and function names are prefixed with the package name.
SET SERVEROUTPUT ON
EXECUTE my_package.display_numbers(2, 6);
2
3
4
5
6
PL/SQL procedure successfully completed.
VARIABLE l_result NUMBER
BEGIN
:l_result := my_package.difference(2, 6);
END;
/
PL/SQL procedure successfully completed.
PRINT l_result
L_RESULT
----------
4
SQL>
Since the package specification defines the interface to the package, the implementation within the package body can be modified without invalidating any dependent code, thus breaking complex dependency chains. A call to any element in the package causes the whole package to be loaded into memory, improving performance compared to loading several individual procedures and functions.
Records
Record types are composite data structures, or groups of data elements, each with its own definition. Records can be used to mimic the row structures of tables and cursors, or as a convenient was to pass data between subprograms without listing large number of parameters.
When a record type must match a particular table or cursor structure it can be defined using the %ROWTYPE attribute, removing the need to define each column within the record manually. Alternatively, the record can be specified manually. The following code provides an example of how records can be declared and used in PL/SQL.
SET SERVEROUTPUT ON
DECLARE
-- Define a record type manually.
TYPE t_all_users_record IS RECORD (
username VARCHAR2(30),
user_id NUMBER,
created DATE
);
-- Declare record variables using the manual and %ROWTYPE methods.
l_all_users_record_1 t_all_users_record;
l_all_users_record_2 all_users%ROWTYPE;
BEGIN
-- Return some data into once record structure.
SELECT *
INTO l_all_users_record_1
FROM all_users
WHERE username = 'SYS';
-- Display the contents of the first record.
DBMS_OUTPUT.put_line('l_all_users_record_1.username=' ||
l_all_users_record_1.username);
DBMS_OUTPUT.put_line('l_all_users_record_1.user_id=' ||
l_all_users_record_1.user_id);
DBMS_OUTPUT.put_line('l_all_users_record_1.created=' ||
l_all_users_record_1.created);
-- Assign the values to the second record structure in a single operation.
l_all_users_record_2 := l_all_users_record_1;
-- Display the contents of the second record.
DBMS_OUTPUT.put_line('l_all_users_record_2.username=' ||
l_all_users_record_2.username);
DBMS_OUTPUT.put_line('l_all_users_record_2.user_id=' ||
l_all_users_record_2.user_id);
DBMS_OUTPUT.put_line('l_all_users_record_2.created=' ||
l_all_users_record_2.created);
l_all_users_record_1 := NULL;
-- Display the contents of the first record after deletion.
DBMS_OUTPUT.put_line('l_all_users_record_1.username=' ||
l_all_users_record_1.username);
DBMS_OUTPUT.put_line('l_all_users_record_1.user_id=' ||
l_all_users_record_1.user_id);
DBMS_OUTPUT.put_line('l_all_users_record_1.created=' ||
l_all_users_record_1.created);
END;
/
l_all_users_record_1.username=SYS
l_all_users_record_1.user_id=0
l_all_users_record_1.created=18-MAR-2004 08:02:17
l_all_users_record_2.username=SYS
l_all_users_record_2.user_id=0
l_all_users_record_2.created=18-MAR-2004 08:02:17
l_all_users_record_1.username=
l_all_users_record_1.user_id=
l_all_users_record_1.created=
PL/SQL procedure successfully completed.
SQL>
Notice how the records can be assigned to each other directly, and how all elements within a record can be initialized with a single assignment of a NULL value.
Object Types
Oracle implements Objects through the use of TYPE declarations, defined in a similar way to packages. Unlike packages where the instance of the package is limited to the current session, an instance of an object type can be stored in the database for later use. The definition of the type contains a comma separated list of attributes/properties, defined in the same way as package variables, and member functions/procedures. If a type contains member functions/procedures, the procedural work for these elements is defined in the TYPE BODY.
To see how objects can be used let's assume we want to create one to represent a person. In this case, a person is defined by three attributes (first_name, last_name, date_of_birth). We would also like to be able to return the age of the person, so this is included as a member function (get_age).
CREATE OR REPLACE TYPE t_person AS OBJECT ( first_name VARCHAR2(30), last_name VARCHAR2(30), date_of_birth DATE, MEMBER FUNCTION get_age RETURN NUMBER ); / Type created. SQL>
Next the type body is created to implement the get_age member function.
CREATE OR REPLACE TYPE BODY t_person AS
MEMBER FUNCTION get_age RETURN NUMBER AS
BEGIN
RETURN TRUNC(MONTHS_BETWEEN(SYSDATE, date_of_birth)/12);
END get_age;
END;
/
Type body created.
SQL>
Once the object is defined it can be used to define a column in a database table.
CREATE TABLE people ( id NUMBER(10) NOT NULL, person t_person ); Table created. SQL>
To insert data into the PEOPLE table we must use the t_person() constructor. This can be done as part of a regular DML statement, or using PL/SQL.
INSERT INTO people (id, person)
VALUES (1, t_person('John', 'Doe', TO_DATE('01/01/2000','DD/MM/YYYY')));
1 row created.
COMMIT;
Commit complete.
DECLARE
l_person t_person;
BEGIN
l_person := t_person('Jane','Doe', TO_DATE('01/01/2001','DD/MM/YYYY'));
INSERT INTO people (id, person)
VALUES (2, l_person);
COMMIT;
END;
/
PL/SQL procedure successfully completed.
SQL>
Once the data is loaded it can be queried using the dot notation.
alias.column.attibute alias.column.function()
The query below shows this in action.
SELECT p.id,
p.person.first_name,
p.person.get_age() AS age
FROM people p;
ID PERSON.FIRST_NAME AGE
---------- ------------------------------ ----------
1 John 5
2 Jane 4
2 rows selected.
SQL>
Collections
Oracle uses collections in PL/SQL the same way other languages use arrays. You can read more about the types of collections available here.
Triggers
Database triggers are stored programs associated with a specific table, view or system events, such that when the specific event occurs the associated code is executed. Triggers can be used to validate data entry, log specific events, perform maintenance tasks or perform additional application logic. The following example shows how a table trigger could be used to keep an audit of update actions.
-- Create and populate an items table and creat an audit log table.
CREATE TABLE items (
id NUMBER(10),
description VARCHAR2(50),
price NUMBER(10,2),
CONSTRAINT items_pk PRIMARY KEY (id)
);
CREATE SEQUENCE items_seq;
INSERT INTO items (id, description, price) VALUES (items_seq.NEXTVAL, 'PC', 399.99);
CREATE TABLE items_audit_log (
id NUMBER(10),
item_id NUMBER(10),
description VARCHAR2(50),
old_price NUMBER(10,2),
new_price NUMBER(10,2),
log_date DATE,
CONSTRAINT items_audit_log_pk PRIMARY KEY (id)
);
CREATE SEQUENCE items_audit_log_seq;
-- Create a trigger to log price changes of items.
CREATE OR REPLACE TRIGGER items_aru_trg
AFTER UPDATE OF price ON items
FOR EACH ROW
BEGIN
INSERT INTO items_audit_log (id, item_id, description, old_price, new_price, log_date)
VALUES (items_audit_log_seq.NEXTVAL, :new.id, :new.description, :old.price, :new.price, SYSDATE);
END;
/
-- Check the current data in the audit table, should be no rows.
COLUMN description FORMAT A10
SELECT * FROM items_audit_log;
no rows selected
-- Update the price of an item.
UPDATE items
SET price = 499.99
WHERE id = 1;
-- Check the audit table again.
COLUMN description FORMAT A10
SELECT * FROM items_audit_log;
ID ITEM_ID DESCRIPTIO OLD_PRICE NEW_PRICE LOG_DATE
---------- ---------- ---------- ---------- ---------- --------------------
1 1 PC 399.99 499.99 19-AUG-2005 10:14:11
1 row selected.
-- Clean up.
DROP TABLE items_audit_log;
DROP TABLE items;
From this you can see that the trigger fired when the price of the record was updated, allowing us to audit the action.
The following trigger sets the current_schema parameter for each session logging on as the APP_LOGON user, making the default schema that of the SCHEMA_OWNER user.
CREATE OR REPLACE TRIGGER APP_LOGON.after_logon_trg AFTER LOGON ON APP_LOGON.SCHEMA BEGIN EXECUTE IMMEDIATE 'ALTER SESSION SET current_schema=SCHEMA_OWNER'; END; /
You can read more about database triggers here.
Error Handling
When PL/SQL detects an error normal execution stops and an exception is raised, which can be captured and processed within the block by the exception handler if it is present. If the block does not contain an exception handler section the exception propagates outward to each successive block until a suitable exception handler is found, or the exception is presented to the client application.
Oracle provides many predefined exceptions for common error conditions, like NO_DATA_FOUND when a SELECT ... INTO statement returns no rows. The following example shows how exceptions are trapped using the appropriate exception handler. Assume we want to return the username associated with a specific user_id value, we might do the following.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 0;
l_username all_users.username%TYPE;
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
DBMS_OUTPUT.put_line('l_username=' || l_username);
END;
/
l_username=SYS
PL/SQL procedure successfully completed.
SQL>
That works fine for user_id values that exist, but look what happens if we use one that doesn't.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 999999;
l_username all_users.username%TYPE;
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
DBMS_OUTPUT.put_line('l_username=' || l_username);
END;
/
DECLARE
*
ERROR at line 1:
ORA-01403: no data found
ORA-06512: at line 5
SQL>
This is not a very user friendly message, so we can trap this error and produce something more meaningful to the users.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 999999;
l_username all_users.username%TYPE;
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
DBMS_OUTPUT.put_line('l_username=' || l_username);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.put_line('No users have a user_id=' || l_user_id);
END;
/
No users have a user_id=999999
PL/SQL procedure successfully completed.
SQL>
It is possible to declare your own named exceptions for application specific errors, or associate them with Oracle "ORA-" messages, which are executed using the RAISE statement. The example below builds on the previous example using a user-defined named exception to signal an application specific error.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 0;
l_username all_users.username%TYPE;
ex_forbidden_users EXCEPTION;
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
-- Signal an error is the SYS or SYSTEM users are queried.
IF l_username IN ('SYS', 'SYSTEM') THEN
RAISE ex_forbidden_users;
END IF;
DBMS_OUTPUT.put_line('l_username=' || l_username);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.put_line('No users have a user_id=' || l_user_id);
WHEN ex_forbidden_users THEN
DBMS_OUTPUT.put_line('Don''t mess with the ' || l_username || ' user, it is forbidden!');
END;
/
Don't mess with the SYS user, it is forbidden!
PL/SQL procedure successfully completed.
SQL>
The code still handles users that don't exist, but now it also raises an exception if the user returned is either SYS or SYSTEM.
We can raise errors and give them a friendly message using the RAISE_APPLICATION_ERROR procedure. The first parameter is a user-defined error number that has to be between -20000 and -20999. Notice the example below uses RAISE_APPLICATION_ERROR, rather than a user-defined named exception. The output includes the error number we specified, but notice we have to trap it with the OTHERS exception handler.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 0;
l_username all_users.username%TYPE;
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
-- Signal an error is the SYS or SYSTEM users are queried.
IF l_username IN ('SYS', 'SYSTEM') THEN
RAISE_APPLICATION_ERROR(-20000, 'Don''t mess with the ' || l_username || ' user, it is forbidden!');
END IF;
DBMS_OUTPUT.put_line('l_username=' || l_username);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.put_line('No users have a user_id=' || l_user_id);
WHEN OTHERS THEN
DBMS_OUTPUT.put_line(SQLERRM);
END;
/
ORA-20000: Don't mess with the SYS user, it is forbidden!
PL/SQL procedure successfully completed.
SQL>
If we want to associate a named exception with the error number, we can use PRAGMA EXCEPTION_INIT as show below. This allows us to trap the error in a named exception handler, rather than having to trap it in the OTHERS handler.
SET SERVEROUTPUT ON
DECLARE
l_user_id all_users.username%TYPE := 0;
l_username all_users.username%TYPE;
ex_forbidden_users EXCEPTION;
PRAGMA EXCEPTION_INIT(ex_forbidden_users, -20000);
BEGIN
SELECT username
INTO l_username
FROM all_users
WHERE user_id = l_user_id;
-- Signal an error is the SYS or SYSTEM users are queried.
IF l_username IN ('SYS', 'SYSTEM') THEN
RAISE_APPLICATION_ERROR(-20000, 'Don''t mess with the ' || l_username || ' user, it is forbidden!');
END IF;
DBMS_OUTPUT.put_line('l_username=' || l_username);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.put_line('No users have a user_id=' || l_user_id);
WHEN ex_forbidden_users THEN
DBMS_OUTPUT.put_line(SQLERRM);
END;
/
ORA-20000: Don't mess with the SYS user, it is forbidden!
PL/SQL procedure successfully completed.
SQL>
My Utopian Development Environment
I wrote a blog post about this many years ago. You can read it here. I think it's worth just spending a little time reiterating some of the main points here. It may not be to everyone's liking, but I've always found it to be the most secure and flexible approach I've come across.
I believe the use of PL/SQL Application Program Interfaces (APIs) should be compulsory. Ideally, client application developers should have no access to tables, but instead access data via PL/SQL APIs, or possibly views if absolutely necessary. The diagram below shows this relationship.
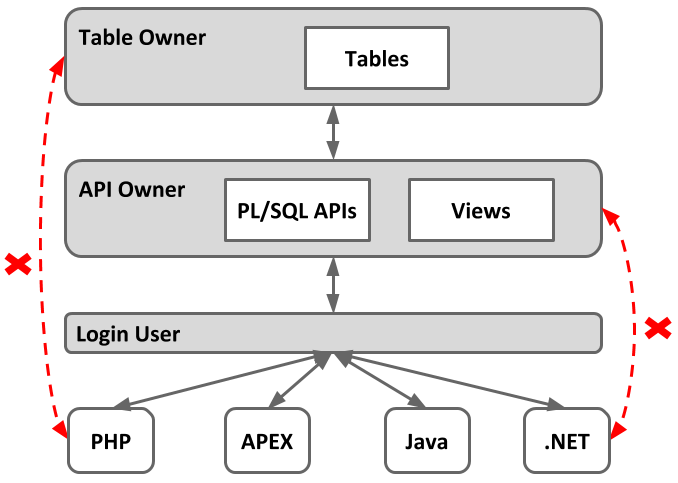
In reality the organisation is likely to be a little more complicated. Maybe something like the example below.
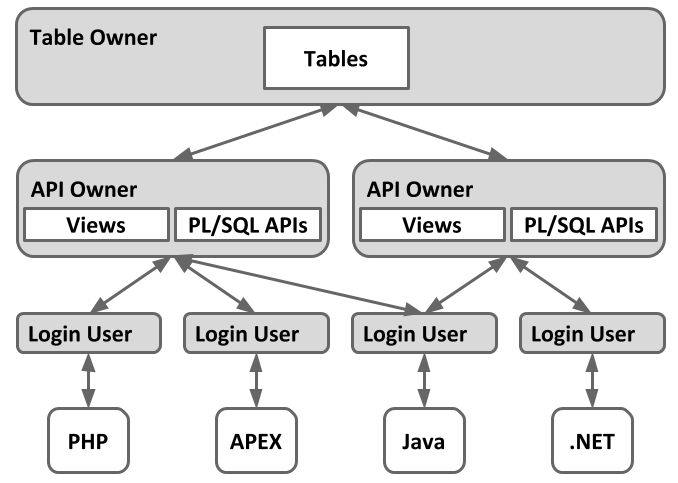
This has a number of beneficial effects, including:
- Security and auditing mechanisms can be implemented and maintained at the database level, with little or no impact on the client application layer.
- It removes the need for triggers as all inserts, updates and deletes are wrapped in APIs. Instead of writing triggers you simply add the code into the API.
- It prevents people who don't understand SQL writing inefficient queries. All SQL should be written by PL/SQL developers or DBAs, reducing the likelihood of bad queries.
- The underlying structure of the database is hidden from the client application developers, so it hides complexity and structural changes can be made without client applications being changed.
- The API implementation can be altered and tuned without affecting the client application layer. Reducing the need for redeployments of applications.
- The same APIs are available to all applications that access the database. Resulting in reduced duplication of effort.
- These API can be presented as web services using XML or JSON. See ORDS.
This sounds a little extreme, but this approach has paid dividends for me again and again. Let's elaborate on these points to explain why this approach is so successful.
It's a sad fact that auditing and security are often only brought into focus after something bad has happened. Having the ability to revise and refine these features is a massive bonus. If this means you have to re-factor your whole application you are going to have problems. If on the other hand it can be revised in your API layer you are on to a winner.
Over-reliance on database triggers is a bad thing in my opinion. It seems every company I've worked for has at one time or another used triggers to patch a “hole” or implement some business functionality in their application. Every time I see this my heart sinks. Invariably these triggers get disabled by accident and bits of functionality go AWOL, or people forget they exist and recode some of their functionality elsewhere in the application. It's far easier to wrap the transactional processing in an API that includes all necessary functionality, thereby removing the need for table triggers entirely.
Many client application developers have to be able to work with several database engines, and as a result are not always highly proficient at coding against Oracle databases. Added to that, some development architectures such as J2EE positively discourage developers from working directly with the database. You wouldn't ask an inexperienced person to fix your car, so why would you ask one to write SQL for you? Abstracting the SQL in an API leaves the client application developers to do what they do best, while your PL/SQL programmers can write the most efficient SQL and PL/SQL possible.
During the lifetime of an application many changes can occur in the physical implementation of the database. It's nice to think that the design will be perfected before application development starts, but in reality this seldom seems to be the case. The use of APIs abstracts the developers from the physical implementation of the database, allowing change without impacting on the application.
In the same way, it is not possible to foresee all possible performance problems during the coding phase of an application. Many times developers will write and test code with unrealistic data, only to find the code that was working perfectly in a development environment works badly in a production environment. If the data manipulation layer is coded as an API it can be tuned without re-coding sections of the application, after all the implementation has changed, not the interface.
A problem I see time and time again is that companies invest heavily in coding their business logic into a middle tier layer on an application server, then want to perform data loads either directly into the database, or via a tool that will not link to their middle tier application. As a result they have to re-code sections of their business logic into PL/SQL or some other client language. Remember, it's not just the duplication of effort during the coding, but also the subsequent maintenance. Since every language worth using can speak to Oracle via OCI, JDBC, ODBC or web services, it makes sense to keep your logic in the database and let every application or data load use the same programming investment.
Of course, you may not always have full control of your development environment, but it's worth bearing these points in mind.
Additional functionality that may be useful to develop your API layer is listed below.
- Pipelined Table Functions
- Using Ref Cursors To Return Recordsets
- Implicit Statement Results
- Proxy User Authentication and Connect Through in Oracle Databases
For more information see:
Hope this helps. Regards Tim...