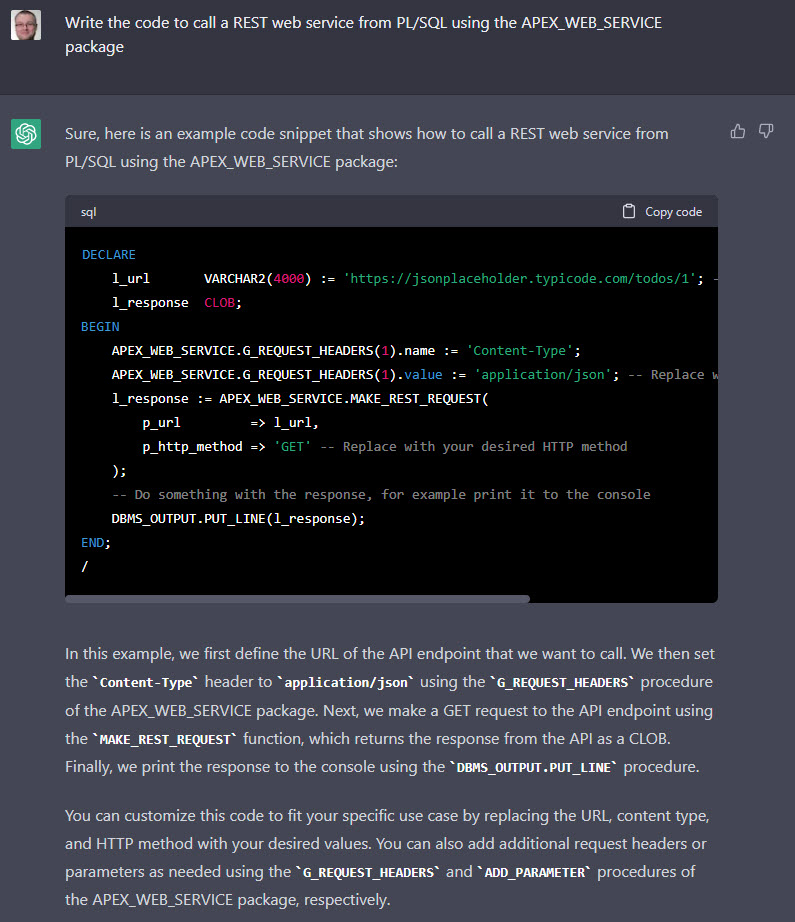
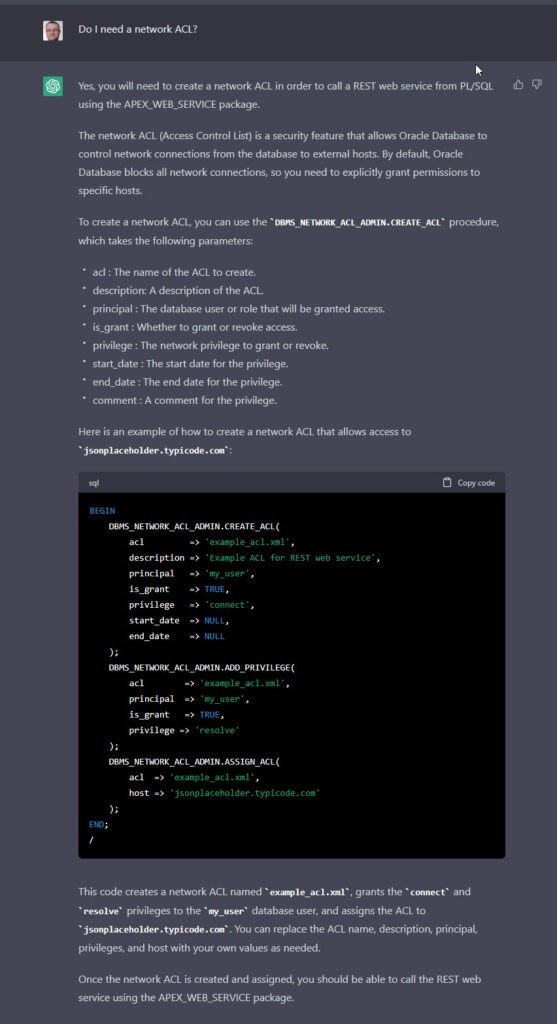
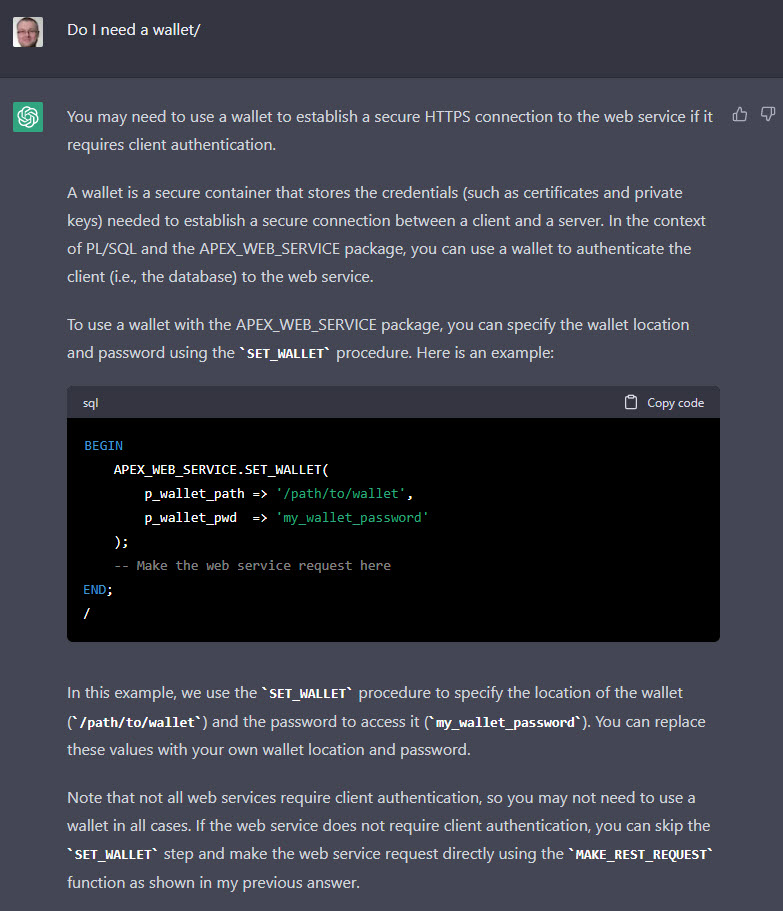
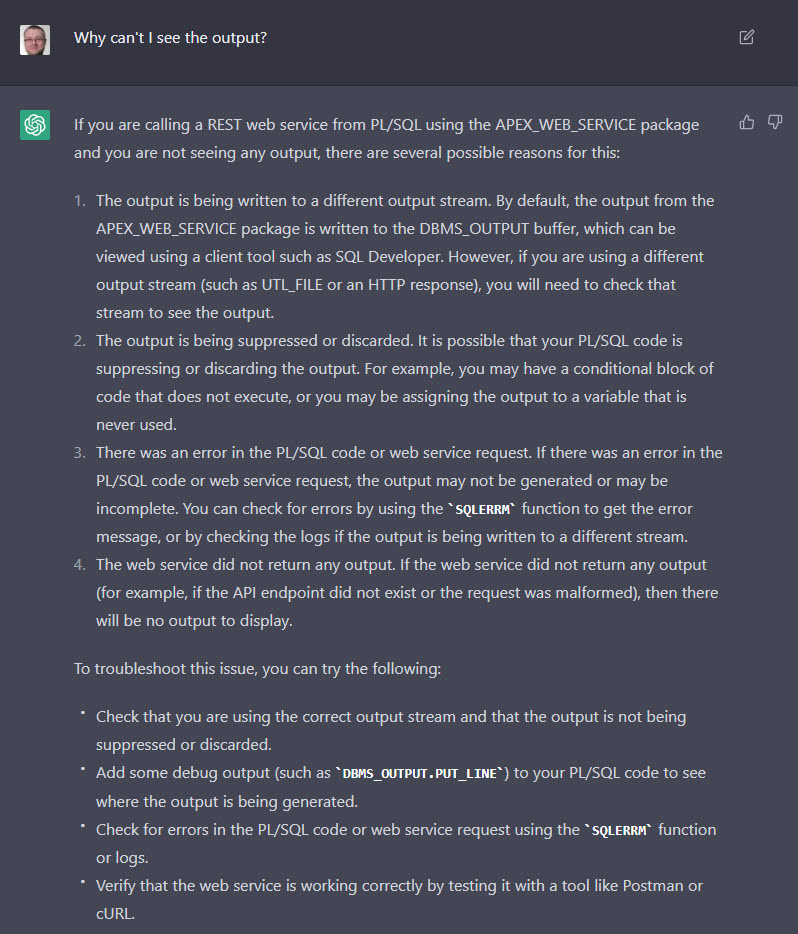
After my previous post on using ChatGPT to write code, I just wanted to say a few words about using artificial intelligence (AI) to generate content such as articles and blog posts.
I’ll list a few specific issues and give my comments on them.

Using AI for inspiration
I watched a video by Marques Brownlee discussing the Bing integration of ChatGPT (here), and one of the things he mentioned was using AI for inspiration. Not expecting AI to create a whole piece of work for you, but using a chat with the AI to come up with ideas.
It reminded me of one of my first attempts at using ChatGPT, which was this. 🙂
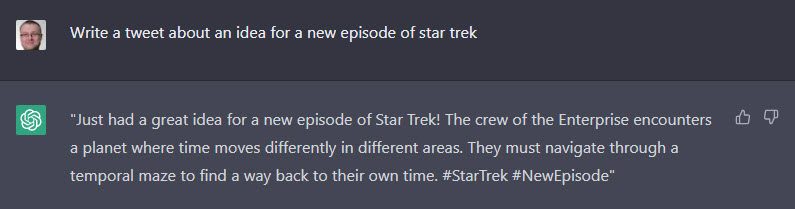
If I were really trying to write something original, I might use this as the inspiration to create my own piece of work.
It should be noted, when I tweeted about this someone replied to say it was similar to the plot of a film they had seen, so we need to be careful the AI is not just stealing someone else’s idea. 🙂
I have no problem with people using AI as part of the generation of ideas. Just be careful that the ideas you get are vaguely original. 🙂
Turning bullet points into prose
One of my friends works for a company that ships physical products. The company has a paper catalogue, as well as an online store. He gets product details from the manufacturers and needs to pretty them up for use in their catalogue and website. He told me he is now using ChatGPT to do this.
To give you an idea of what he is doing I copied some text of Amazon and asked ChatGPT to make it a bit nicer.
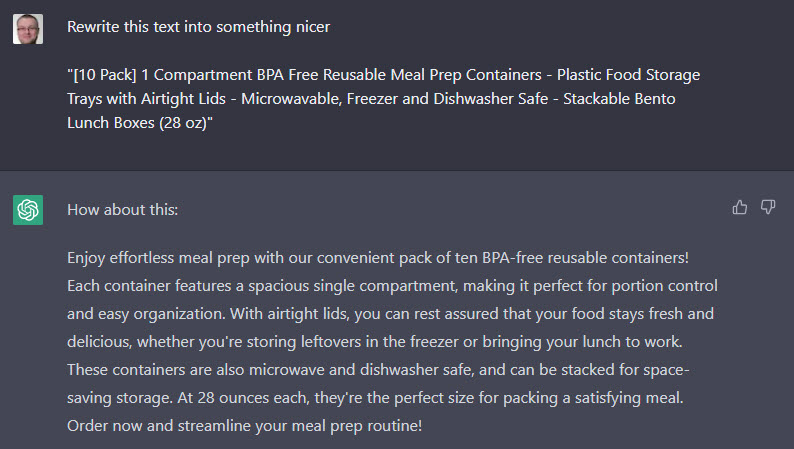
In this case we aren’t expecting the AI to get facts from the internet. We are providing the base information and using the AI as a writing aid.
This is another use case I think it totally fine. It’s merely a tool that saves you a bit of time. People already use tools like Grammarly to help with spelling and grammar. This just seems like a logical next step to me.
It makes mistakes
The AI doesn’t know anything about the content it is generating, so it can’t fact check itself. Here’s another example of something I Tweeted out. I asked ChatGPT if I should use leading or trailing commas when writing SQL.
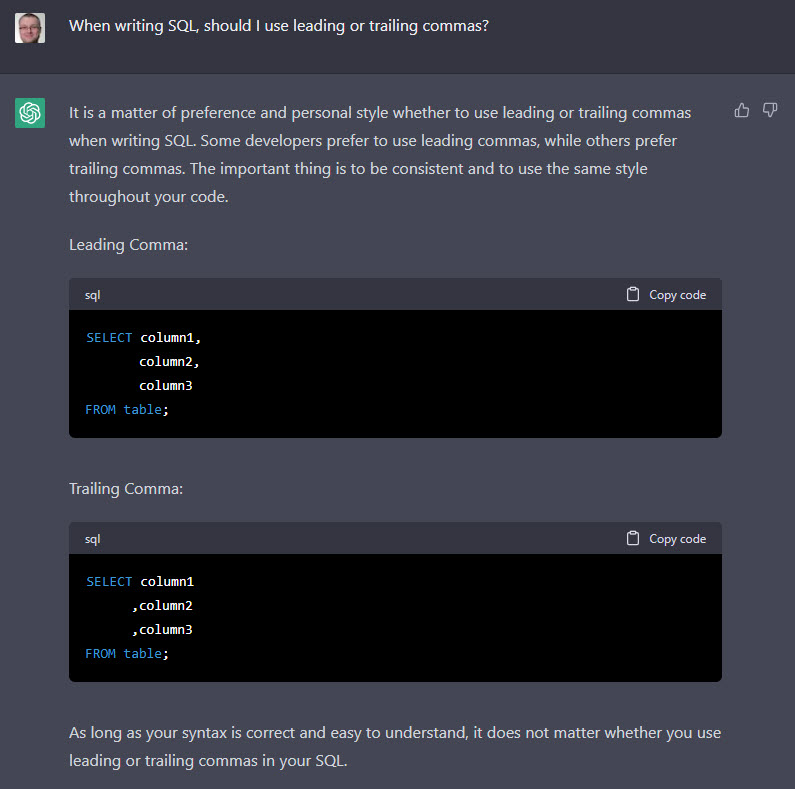
It came back with a nice answer saying it is a personal preference, and gave an example of the two styles. The slight problem was the examples demonstrate the opposite of what they are meant to. 🙂
A human can pick that up, correct it and we will get something that seems reasonable, but it proves the point that we can’t blindly accept the output of AI content generation. We need to proof read and fact check it. This can be difficult if it doesn’t cite the sources used during the generation.
Sources and citations
Currently ChatGPT is based on a 2021 data set. When we use it we get no citations for the sources of information used during the generation process. This causes a number of problems.
- It makes it hard to fact check the information.
- It is impossible to properly cite the sources.
- We can’t read the source material to check the AI’s interpretation is correct.
- We can’t make a judgement on how much we trust the source material. Not all sources are reputable.
- We can’t check to see if the AI has copied large pieces of text, leaving us open to copyright infringement. The generated text is supposedly unique, but can we be certain of that?
The Bing integration of ChatGPT does live searches of the internet, and includes citations for the information sources used, which solves many of these problems.
Copyright
AI content generation is still fairly new, but we are already seeing a number of issues related to copyright.
There are numerous stories about AI art generation infringing the copyright of artists, with many calling for their work to be opted out of the training data sets for AI, or to be paid for their inclusion. There is a line between inspiration and theft, and many believe AI art generation has crossed it. It’s possible this line has already been crossed in AI text generation also.
There is also the other side of copyright to consider. If you produce a piece of work using AI, it’s possible you can’t copyright that piece of work, since copyright applies to work created by a human. See the discussion here.
You can argue about the relative amounts of work performed by the AI and the human, but it seems that for 100% AI generation you are skating on thin ice. Of course, things can change as AI becomes more pervasive.
Who is paying for the source material to be created?
Like it or not, the internet is funded by ad revenue. Many people rely on views on their website to pay for their content creation. Anything that stops people actually visiting their site impacts on their income, and will ultimately see some people drop out of the content creation space.
When Google started including suggested answers in their Google search results, this already meant some people no longer needed to click on the source links. ChatGTP takes that one step further. If it becomes common place for people to search on Bing (or any other AI backed search engine), and use the AI generated result presented, rather than visiting the source sites, this will have a massive impact on the original content creators. The combination of this and ad blockers may mean the end for some content creators.
If there is no original content on the internet, there is nothing for AI to use as source material, and we could hit a brick wall. Of course there will always be content on the internet, but I think you can see where I’m going with this.
So just like the copyright infringement issues with AI art, are we going to see problems with the source material used for AI text generation? Will search engines have to start paying people for the source material they use? We’ve already seen this type of issue with search engines reporting news stories.
The morality of writing whole posts with AI
This is where things start to get a bit tricky, and this is more about morality and ethics, rather than content.
Let’s say your job is to write content. Someone is paying you to spend 40 hours a week writing that content, and instead you spend a few minutes generating content with AI, and use the rest of the time to watch Netflix. You can argue you are delivering what is asked of you and making intelligent use of automation, or that you are stealing from the company because you are being paid for a job you are not doing. I’m guessing different people will have a different take on this from a moral perspective.
Continuing with the theme of being paid to write, what if the company you are working for is expecting to have copyright control over the work you produce? If it can be determined it is AI generated, they can’t copyright it, and that work can be republished with no comeback. I can see that making you rather unpopular.
Education establishments already use software to check for plagiarism. The use of AI is already making educational establishments nervous. OpenAI, the creators of ChatGPT, have already created an AI Text Classifier (discontinued) to identify text that has been generated by AI. I can only imagine these types of utilities will become common place, and you could find yourself in hot water if you are passing off AI generated work as your own. You will certainly lose your qualifications for doing it.
Many people use their blogs as an indication of their expertise. They are presenting themselves as well versed in a subject, which can then lead to other opportunities, such as job offers, invitations to conferences and inclusion in technology evangelism programs. If it becomes apparent the content is not your own work, it would seem logical that your professional reputation would be trashed, and you would lose some or all of the benefits you have gained.
Conclusion
There is no right and wrong answer here, but in my opinion it’s important we use AI as a tool, and not a mechanism to cheat. Where we draw the line will depend on the individual, and the nature of the work being done. Also, it’s possible that line in the sand will change over time…
Check out the rest of the series here.
Cheers
Tim…