I had a call with some folks from DBmarlin back in June and they gave me a demo of their new database performance monitoring product, which supports any mix of on-prem and cloud databases. You can see the kind of stuff they do in the videos at the end of the post. One of the things I thought was cool was it tracks changes and overlays them on their timeline, so you can see if a change results in a significant difference in performance. Neat!
I mentioned this on Twitter at the time and Ilmar Kerm responded with this message.
“Good idea to overlay dB changes… this gives me an idea to start collecting all changes from liquibase databasechangelog tables and annotate grafana dashboards with them”
The next day he came back with this post.
“Done and deployed 🙂 Collecting Liquibase databasechangelog entries into central InfluxDB measurement. Added these events as annotations to grafana + dashboard just to browse all individual executed changesets as a text log. I like it.”
You can see an image of his dashboard here.
A few days ago I got an email from the DBmarlin folks again asking if I wanted to check out their Liquibase integration, inspired by Ilmar, so on Friday last week we had that call.
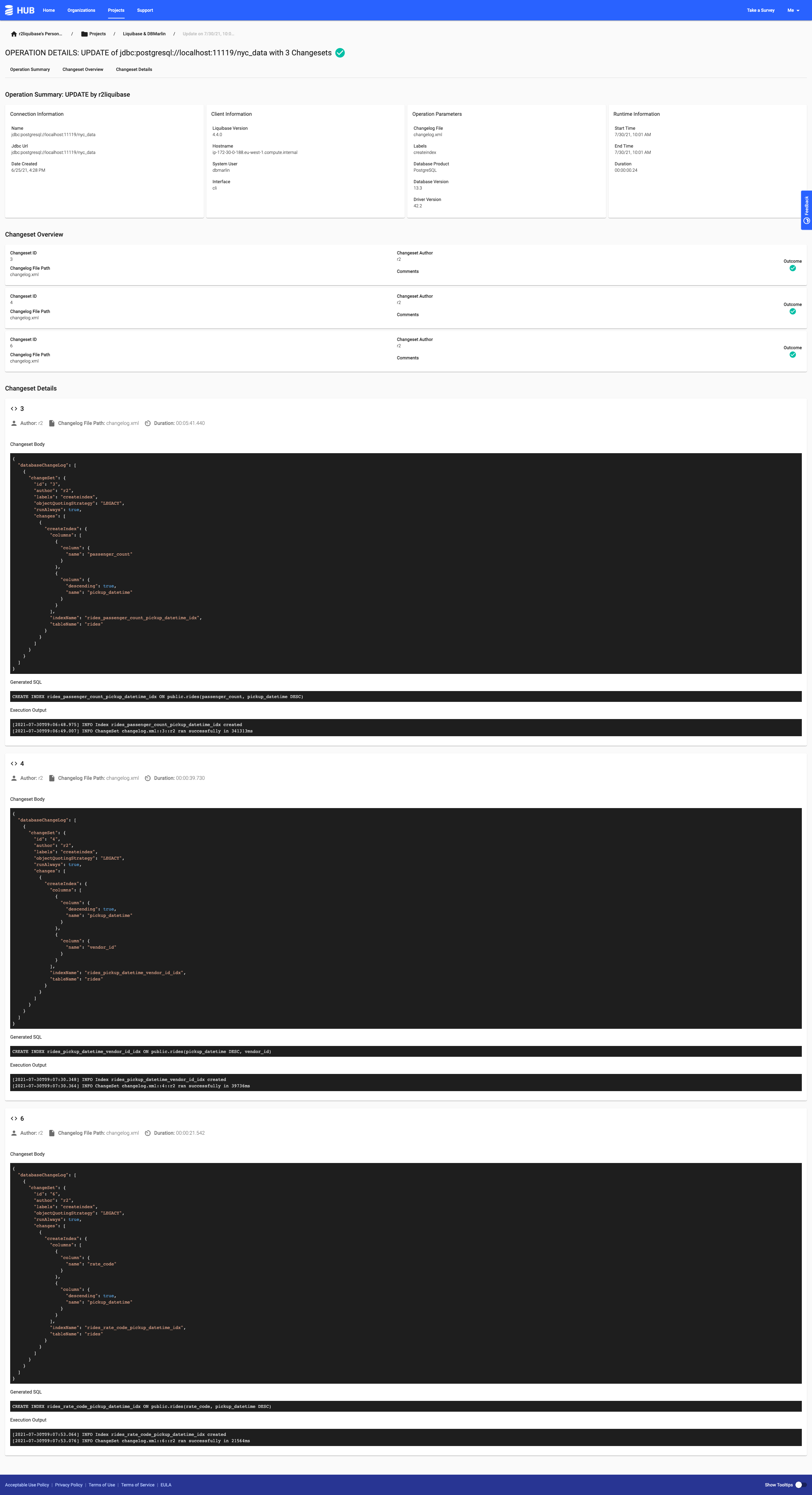
Their implementation is different to Ilmar’s, as they don’t reference the DATABASECHANGELOG table. Instead they’ve got a jar file that integrates with the Liquibase client to give them the change information, and allow them to link through to Liquibase Hub. The Liquibase integration is available from this repo on GitHib.
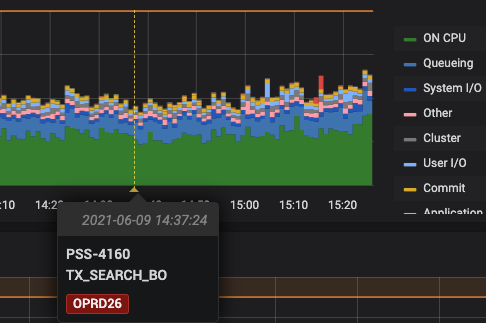
If you click on the image below to expand it, you will see the timeline with the changes (see my red arrows), and the list of changes at the bottom. Notice the Liquibase change I’ve highlighted.
Clicking on the link in the Liquibase change takes you to Liquibase Hub, where you can get more details about the change.
I really like this.
This is hot off the press. They are looking for people to kick the tyres on this and give them some feedback, so if you’re currently using the Liquibase client and Liquibase Hub with your databases (Oracle, PostreSQL, SQL Server, MySQL, CockroachDB etc.), give Russell (russell.luke@applicationperformance.com) a shout and have a play! You could get a free copy of DBmarlin for your feedback.
By the way, they also do Jenkins integration. See here. 🙂
Cheers
Tim…
BTW, this is not a sponsored post. I just like what they are doing with this product, so I thought it was worth a shout out.
When I shutdown some VMs before the VirtualBox upgrade, I noticed Vagrant 2.2.18 had been released. Downloads here.
I’ll need to rebuild my Vagrant boxes again, so I thought I should check if there was a new Packer version. Sure enough, Packer 1.7.4 was available. Downloads here. It came out just over a week ago, but I hadn’t noticed.
They are all installed now, so I’ve just got to start doing some Vagrant box builds. Happy days… 🙂
Cheers
Tim…
Update: I used Packer to rebuild my OL7 and OL8 vagrant boxes. They are now uploaded to Vagrant Cloud.
If you’ve been using AdoptOpenJDK to download OpenJDK, you will have noticed for the last few months there has been a message at the top of the screen with this link.
That message recently changed to include the following message.
“Our July 2021 and future releases will come from Adoptium.net“
When you go to the link you will see a very familiar looking page layout, with some slightly different branding. 🙂
They July updates are scheduled for the end of July, so you’ll have to wait a bit. In previous quarters they’ve been less than 3 working days of the initial security announcement, but I guess the reorganization has delayed things somewhat.
There was a Teams discussion at work and this book was mentioned, so I thought I would give it a go. I must admit I was a little nervous about it because I really didn’t like The Unicorn Project (see here) and it kind-of put me off reading anything else with Gene Kim’s name associated with it.
The Good
There are two forwards. The first by Martin Fowler and the second by Courtney Kissler. By the time I finished reading the forward by Courtney Kissler I felt really hyped up and I couldn’t wait to get into it. Reading it back now I’m not sure why it resonated with me so much, but it did…
The book is split into two main parts. The first part discusses the conclusions from the research. I think there are endless quotable moments here. I started to write some down, thinking I could incorporate some into this post, but there were too many, so I decided not to. 🙂 If you’ve read other books on DevOps and Lean, there won’t be a lot that is new to you, but these conclusions are evidence-based, rather than just speculation and rose coloured spectacles views of projects gone by. One of the things that irritates me with some books is I wonder how much is real, and how much is rewriting history to fit the narrative. Evidence based feels more real.
The second part of the book was more focused on the evidence that was gathered that lead to the conclusions. That sounds like it could be a little dry, but I think it worked quite well.
The Bad and the Ugly
I don’t have anything really negative to say about the book. The bad and the ugly is more down to the way I felt as the book came to a conclusion. When I’m reading these books I get a bit lost in them, and feel like I can make a difference. I’m all enthusiastic, but when they are over I come crashing down to earth. Discussions of culture change driven from the top, with senior management developing a culture of learning, leave me desolate. Discussions of the teams and people needed for success make me wonder if we have the raw materials to do this. It just seems insurmountable…
There was one section that mentioned working with 3rd party apps, and I was really interested to see what they said, but it was rather vague and disappointing, which I could have predicted. That was probably my only real gripe, but the book was unapologetically focused on software development, so I can’t really hold this point against it. 🙂
Conclusion
If you are into the whole DevOps, Lean and organisational transformation stuff I think it’s worth taking a look. You aren’t necessarily going to walk away with new insights, but you might get a better understanding of how you can quantify a transformation you are taking part in. It’s also nice to be reminded of stuff you’ve read before…
The star of today’s video is Lonneke Dikmans, who always seems to be doing something cooler than me. Check out DoeMee, an app that “offers a total model for contemporary governance”.
The 21.2 version of ORDS and SQLcl dropped at the start of the month. I guess I missed that, as the first I noticed was Alex Nuijten talking about SQLcl 21.2 nearly two weeks later. As soon as I realised they had arrived I downloaded them and went to work.
All of the relevant Vagrant and Docker builds were updated to use ORDS 21.2, SQLcl 21.2 and Tomcat 9.0.50.
The Oracle security patches come out next week, so these builds will be updated again to include the latest versions of OpenJDK (AdoptOpenJDK) and the Oracle database patches where necessary.
SQL Developer and Database Modeler
These aren’t anything to do with my builds, but thought is was worth mentioning. The 21.2 version of SQL Developer and Data Modeler have been available for the last few days. You can read Jeff’s announcement here.
This started a bit of a debate on Twitter about how people patch their databases. In this post I want to touch on a few points that came out Pete’s post an some of the other Twitter comments.
You have to have a plan!
An extremely important point made by Pete was you have to have a plan. That doesn’t have to be the same for everyone, and there may be compromises due to constraints in your company, but that doesn’t stop you making a plan. Your plan might be:
We will start a new round of patching immediately when a new on-off patch is released, and every quarter with the security announcements. I can’t see how this is possible.
We will patch every quarter with the security announcements. That’s what my company does.
We will patch once per (six months, year etc.)
Hopefully your plan will not be:
We will never patch and person X will take the blame when we have a problem.
Release Updates (RUs) or Release Update Revisions (RURs)
Database quarterly patches are classified as release updates (RUs) and release update revisions (RURs). First let’s explain what they are.
Release Updates (RUs) : These are like the old proactive bundle patches. They contain bug fixes, security fixes and limited new features. Let’s call that “extra stuff”. In 19c the blockchain tables and immutable tables features were introduced in RUs. Backporting and new features can introduce new risks.
Release Update Revisions (RURs) : These are just bug fixes and security fixes. In theory these are safer than RUs as less new stuff is introduced, but… See below.
So from first glance you are saying to yourself I want the safest option, so I want to go for RURs. The problem is RURs aren’t like the old security patches that you could continue applying forever. Ultimately you have to include all the “extra stuff” from the previous RUs, but you get the option of doing it later. This page in the documentation explains things quite well.
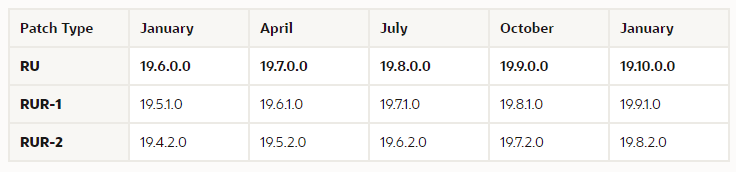
This table from that link is quite useful, showing you what version you will be on during a quarterly patching cycle.
What does this mean?
If you patch using the RUs, you are going to the latest and greatest each quarter.
If you use RUR-1, you are constantly 1 quarter behind on the RUs extra content, but you add in the missing bug fixes and security fixes using the RUR-1 patch.
If you use RUR-2, you are constantly 2 quarters behind on the RUs extra content, but you add in the missing bug fixes and security fixes using the RUR-2 patch.
In all cases you have the latest bug fixes and security fixes. You are just delaying getting the “extra bits”. So at first glance it seems like you might as well go with the RUs. The issue is some of the RUs are a bit buggy. If you go for the RUR-1 or RUR-2 there is a chance the bugs introduced in the base RU have been fixed in the subsequent RURs for that RU. So we could say this.
RUs: Oracle have zero time to identify and fix the bugs they’ve introduced in the RU.
RUR-1: Oracle have 3 months to find and fix the bugs they’ve introduced in the base RU.
RUR-2: Oracle have 6 months to find and fix the bugs they’ve introduced in the base RU.
I tend to stick with the RUs, although I am considering changing. Ilmar Kerm said he’s found RUs too buggy and tends to stick with the RUR-1 approach. I guess a more conservative approach would be to stick with the RUR-2 approach.
Your experience of the RUs verses the RURs will depend on what features you use, what extra stuff Oracle decide to include in the RU and what they break by including that extra stuff. The biggest problem I got was 19.10 breaking hot-cloning of PDBs, which was kind-of important. If I had used the RUR-1 approach I would never have seen that issue. Different people using different features see different bugs.
How good is your testing?
The biggest factor in the decision of which approach to take is probably the quality of your testing.
If your testing of applications against new patches is good, you can probably stick with the RUs. If the RU fails testing, go with the RUR-1 that quarter.
If you just work on the “generally considered safe” approach, meaning you apply the patches and don’t do any testing, maybe you should be using the RUR-1 or RUR-2 approach!
The ultra-conservative approach would be to stick with the RUR-2 approach.
Just patch!
Regardless of which approach you take, you’ve got to have a plan, and you should be patching. I know some of you don’t care about patching, and you are fools. I know some of you would like to patch, but your companies are dinosaurs. All I can say to you is keep trying.
In my current company we never used to patch. I spent years sending out quarterly reports summarising all the vulnerabilities in our systems and still nothing. Eventually a few other people jumped on the bandwagon, we had a couple of embarrassing issues, and the constant threat of GDPR gave us some more leverage. Now we have a quarterly patching schedule for all our databases and middle tier servers. We are not perfect, but it can be done.
Even now, we still have questions like, “can we miss out this quarter?”, but we push back very hard against this. One quarter becomes two, becomes three, becomes never.
New patches on the 20th July (see here). Good luck everyone!
Cheers
Tim…
PS. If you are not patching externally facing WebLogic servers you might as well close your company now. You have already given all your data away. Good luck with that GDPR fine…
Over a decade ago Cary Millsap was doing talks at Oracle conferences called “Thinking Clearly About Performance”. One of the points he discussed was identifying the big bottlenecks and dealing with those, rather than focusing on the little things that weren’t causing a problem. For example, if a task is made up of two operations where one takes 60 seconds to complete and the other one takes 1 second to complete, which one will give the most benefit if optimized?
This is the same issue when we are looking at automation to improve flow in DevOps. There are a whole bunch of things we might consider automating, but it makes sense to try and fix the things that are causing the biggest problem first, as they will give the best return. In DevOps and Lean terms that is focusing on the constraint. The weakest link in the chain. (see Theory of Constraints).
Lost in Automation
The reason I mention this is I think it’s really easy to get lost during automation. We often focus on what we can automate, rather than what needs automating. With my DBA hat on it’s clear my focus will be on the automation of provisioning and patching databases and application servers, but how important is that for the company?
If the developers want to “build & burn” environments, including databases, for their CI/CD pipelines, then automation of database and application server provisioning is really important as it might happen multiple times a day for automated testing.
If the developers use a more traditional dev, test, prod approach to environments, then the speed of provisioning new systems may be a lot less important to the overall performance of the company.
In both cases the automation gives benefits, but in the first case the benefits are much greater. Even then, is this the constraint? Maybe the problems is it takes 14 days for approval to run the automation? 🙂
It’s sometimes hard for techies to have a good idea of where they fit in the value chain. We are often so focused on what we do, and don’t have a clue about the bigger picture.
Before we launch into automation, we need to focus on where the big problems are. Deal with the constraints first. That might mean stopping what you’re doing and going to help another team…
Don’t Automate Bad Process
We need to streamline processes before automating them. It’s a really bad idea to automate bad processes, because they will become embedded for life. It’s hard enough to get rid of bad processes because the, “it’s what we’ve always done”, inertia is difficult to overcome. If we add automation around that bad process we will never get rid of it, because now people will complain we are breaking the automation if we alter the process.
Another thing Cary talked about was removing redundant steps. You can’t make something faster than not doing it in the first place. 🙂 It’s surprising how much useless crap becomes embedded in processes as they evolve over the years.
The process of continuous improvement involves all aspects of the business. We have to be willing to revise our processes to make sure they are optimal, and build our automation around those optimised processes.
I’m not advocating compulsory tuning disorder. We’ve got to be sensible about this stuff.
Know When to Cut Your Losses
The vast majority of examples of automation and DevOps are focussed on software delivery in software development focused companies. It can be very frustrating listening to people harp on about this stuff when you work in a mixed environment with a load of 3rd party applications that will never be automated because they can’t be. They can literally break every rule you have in place and you are still stuck with them because the business relies on them.
You have to know where to cut your losses and move on. There will be some systems that will remain manual and crappy for as long as they are in your company. You can still try and automate around them, and maybe end up in a semi-automated state, but forget wasting your time trying to get to 1000 deployments a day. 🙂
I think it makes sense for us to all to try and get a better understanding of the bigger picture. It can be frustrating when you’ve put in a lot of work to automate something and nobody cares, because it wasn’t perceived as a problem in the big picture. I’m not suggesting we all have to be business analysts and system architects, but it’s important we know enough about the big picture so we can direct our efforts to get the maximum results.
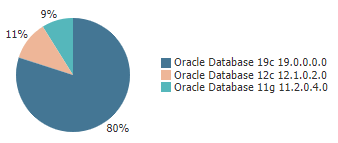
I’ve mentioned database upgrades a few times over the last year or more. Like many others, we are pushing hard to get everything upgraded to 19c. Over the last couple of weeks a bunch more systems got upgraded, and we are now looking like this.
The remaining 11.2 and 12.1 databases are all in various stages of migration/upgrade. I would not curse us by giving a deadline for the final databases, but hopefully soon!
The reason for mentioning that theme song is it starts with the words, “It’s been a long road getting from there to here”, and that is exactly how it feels.
Many of the database upgrades are technically simple, but the projects surrounding them are soul destroying. Getting all the relevant people to agree and provide the necessary resources can be really painful. This is especially true for “mature” projects, where the, “if it ain’t broke, don’t fix it”, mentality is strong. I wrote about the problems with that mentality here.
I’m not going to give you any blinding insights into how to do your database upgrades, because every upgrade is potentially unique, as I discussed here.
We always go for the multitenant architecture (CDB/PDB) unless there is a compelling reason not to. I think we only have one non-CDB installation of 19c because of a vendor issue. None of our other 3rd party applications have had a problem with using PDBs, provided we’ve made sure they connect with the service, not a SID. We don’t use the USE_SID_AS_SERVICE_listener_name parameter. I would rather find and fix the connection issues than rely on this sticking plaster fix.
In know I’ve said some of these things before, but they are worth repeating.
Oracle 19c is the current long term release, so it’s going to have support for a longer time than an innovation release.
Oracle 21c is an innovation release. Even when the on-prem version does drop, you probably shouldn’t use it for your main systems unless you are happy with the short support lifespan.
I recently heard there won’t be an Oracle 22c, so the next release after Oracle 21c will be Oracle 23c, which is currently slated to be the next long term release.
In short, get all your databases to Oracle 19c, and you should probably stick there until Oracle 23c is released, unless you have a compelling case for going to Oracle 21c.