Having recently put out a post about database patching, I was interested to know what people out in the world were doing, so I went to Twitter to ask.
As always, the sample size is small and my followers have an Oracle bias, so you can decide how representative you think these number are…
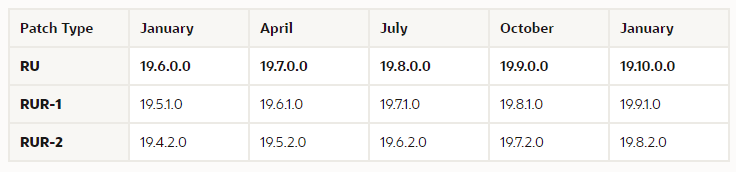
Patching Frequency
Here was the first question.
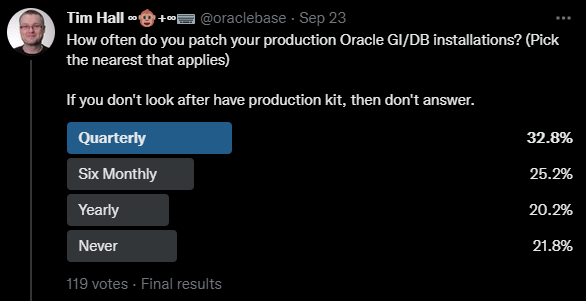
There was a fairly even spread of answers, with about a third of people doing quarterly patching, and a quarter doing six-monthly patching. I feel like both these options are reasonable. About 20% were doing yearly patching, which is starting to sound a little risky to me. The real downer was over 22% of people never patch their databases. This is interesting when you consider the recent announcement about monthly recommended patches (MRPs).
For those people that never patch, I can think of a few reasons off the top off my head why.
- Lack of testing resource. I think patch frequency has more to do with testing than any other factor. If you have a lot of databases, the testing resource to get through a patching cycle can be quite considerable. This is why you have to invest some time and money into automated testing.
- If it ain’t broke, don’t fix it. The problem is, it is broken! How long after your system has been compromised will it be before you notice? How are your customers going to feel when you have a data breach and they find out you haven’t even taken basic steps to protect them? I don’t envy you explaining this…
- Fear of downtime. I know downtime is a real issue to some companies, but there are several ways to mitigate this, and you have to balance the pros and the cons. I think if most people are honest, they can afford the downtime to patch their systems. They are just using this as an excuse.
- Patching is risky. I understand that patches can introduce new issues, but that is why there are multiple ways to patch, with some being more conservative from a risk perspective. I think this is just another excuse.
- Out of support database versions. I think this is a big factor. A lot of people run really old versions of the database that are no longer in support, and are no longer receiving patches. I don’t even think I need to explain why this is a terrible idea. Once again, how are you going to explain this to your customers?
- Lack of skills. We like to think that every system is looked after by a qualified DBA, but the reality is that is just not true. I get a lot of questions from people who are SQL Server and MySQL DBAs that have been given some Oracle databases to look after, and they freely admit to not having the skills to look after them. Even amongst Oracle DBAs there is a massive variation in skills. Oracle patching has improved over the years, but it is still painful compared to other database engines. Just saying.
Type of Patching
This was the second question.
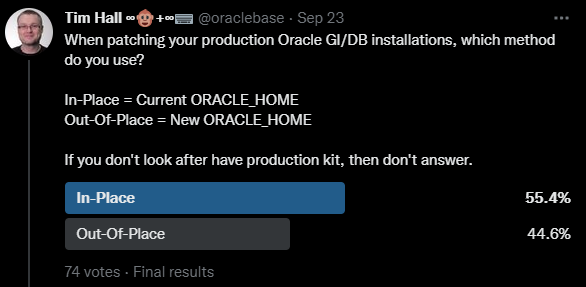
In-Place = Current ORACLE_HOME
Out-Of-Place = New ORACLE_HOME
This was a fairly even split, with In-Place winning by a small margin. Oracle recommend Out-Of-Place patching, but I think both options are fine if you understand the implications. I discussed these in my previous post.
Conclusion
I think of patch frequency in a similar way to upgrade frequency. If you do it very rarely, it’s really scary, and because nobody remembers what they did last time, there are a bunch of problems that occur, which makes everyone nervous about the next patch/upgrade. There are two ways to respond to this. The first is to delay patching and upgrades as long as possible, which will result in the next big disaster project. The second is to increase your patch/upgrade frequency, so everyone becomes well versed in what they have to do, and it becomes a well oiled machine. You get good at what you do frequently. As you might expect, I prefer the second option. I’ve fought long and hard to get my company into a quarterly patching schedule, and it will only decrease in frequency over my dead body!
Assuming the results of these polls are representative of the wider community, I feel like Oracle need to sit up and take notice. Patching is better than it was, but “less bad” is not the same as “good”. It is still too complicated, and too prone to introducing new issues IMHO!
Cheers
Tim…