Oracle have released Oracle Database 23ai. You can watch the announcement video here, and read the announcement blog post here.
I don’t think I can add much to that, but I just want to talk about how this affects me as a customer and as a content creator.
Customer View
We’ve been waiting for Oracle Database 23 for a very long time. As I mentioned in this post, most of the upgrades I’ve been asked to do in my career are not driven by new features. They are driven by a need to stay in support.
Database upgrades are pretty simple from a technical perspective, but from a project perspective they are a nightmare. It takes ages to get everyone to agree to them, and then an eternity to actually test things before progressing to production. Any delays have a massive impact on this process.
We are in the process of migrating loads of our databases off Oracle Linux 7 and on to Oracle Linux 8 or 9 depending on 3rd party vendor support. We have to go through a whole testing cycle to complete this. If Oracle 23 had been released last year, many of these migrations would have gone directly to the new OS and new database version. You can argue the virtues of doing things separately or as a big bang, but our reality is testing resources are our biggest blocker, so having to test all our systems twice, once for the OS migration and once for the DB migration, represents a problem.
The delay of Oracle 23 on-prem has been a big headache. When I saw the announcement of Oracle Database 23ai I was sure it would include the on-prem version of the database. It does not. That was a bitter disappointment!
Content Creator View
I realise most of the people reading this are not content creators, and these issues are unlikely to affect you, but here goes…
Over the last 18 months I’ve written a bunch of articles. With the release of 23c Free I was able to publish most of them. As part of the Oracle community hype machine we’ve been encouraged to produce as much content about 23c as possible. There are a lot of us that will either have to go back and edit our 23c content, or leave the internet full of content for a version that doesn’t exist.
For the most part 23ai is just 23c with a different badge, so much of this can be done with a search and replace, along with the appropriate redirects. Where it is a bigger problem is for those that have published videos on YouTube, as those need to be redone and republished. There is no quick in-place edit. I’m one of the lucky ones here, as I made the decision to wait for the on-prem release before starting any videos, but some people will have a really painful job to do if they want things to keep current.
What I’m doing now
I’ve started the process.
My 23c index page now redirects to 23ai. It still contains all the 23c articles, but over the coming weeks they will change. All the old URLs will be redirected, so the world won’t be filled with broken links. It’s just going to take some time. If any of you notice any problems, just give me a shout.
I updated my vagrant builds. The 23c Free on OL8 build is now 23ai Free on OL8 build. There is also an OL9 build. You can find them here.
So I’m a few steps back compared to where I was before the announcement. I’m still waiting for the on-prem release, and now I’ve got to rework a bunch of existing content…
We are already seeing some backlash against AI in the tech press. I hope the new name doesn’t come back to haunt Oracle.
I had a particularly annoying problem with Oracle auditing a few days ago. I thought I would write about it here in case anybody knows a solution, or if anyone at Oracle cares to add the functionality I need. 🙂
The problem
I was asked to audit selects against tables in a particular schema when issued by several users. For the sake of this post let’s assume the following.
SCHEMAOWNER : The owner of the tables that are to be audited.
USER1, USER2, USER3 : The three users whose select statements are to be audited.
So I decided the write an audit policy.
Option 1 : Audit all selects, regardless of schema
My first thought was to do this.
create audit policy my_select_policy actions select when q'~ sys_context('userenv', 'session_user') in ('USER1','USER2','USER3') ~' evaluate per session container=current;
The problem is it produced masses of audit records, most of which were referencing selects against objects owned by other schemas. I have so many records I can’t actually purge the audit trail. I’m having to wait until the next partition is created in a month, so I can drop the current partition and shrink the data files. 🙁
Option 2 : Explicitly list all objects to be audited
So I need to make the policy more granular, which I can do by explicitly referencing all objects I want to audit, like this.
create audit policy my_select_policy actions select on schemaowner.tab1, select on schemaowner.tab2, select on schemaowner.tab3 when q'~ sys_context('userenv', 'session_user') in ('USER1','USER2','USER3') ~' evaluate per session container=current;
The problem is there are loads of tables in the schema, so doing this is a pain. I could generate the statement using a script, but even then if someone adds a new table the audit policy wouldn’t pick it up.
What I really want
What I really want is to be able to limit the action to a specific schema. The specific syntax is not important. The result is what matters. Maybe something like this.
-- Use and explicit schema reference, create audit policy my_select_policy actions select on schema schemaowner when q'~ sys_context('userenv', 'session_user') in ('USER1','USER2','USER3') ~' evaluate per session container=current;
Thoughts
I don’t believe the current syntax for audit policies allows them to be limited by schema, so I’m faced with generating masses of unnecessary audit records, or having to explicitly name every table. 🙁
This all sounded kind-of familiar, and when I did a bit of Googling I found this note by Pete Finnigan. So I’m not alone in finding this frustrating.
We had a pretty momentous occasion recently. We finally got rid of the last of our HP-UX servers, and with it the last of our Oracle 11g databases and Oracle Forms apps.
We use VMware virtual machines running Oracle Linux for nearly all our databases. We pushed really hard over the last couple of years to get everything migrated to 19c. Despite this, there were two projects that were left behind on HP-UX and Oracle 11g. They were effectively dead projects, from the time before we moved to Oracle Cloud Apps, about 5 years ago. We couldn’t get rid of them because people wanted to look at the historical data, but there was very little appetite to do anything with them…
Finally, over the last year we’ve had an archive project running, which involved moving the databases on to Oracle Linux and upgrading to 19c. That bit was easy. The other bit of the project involved building two new APEX apps to replace a 3rd party application and an old Oracle Forms 11g app. Those went live a few months ago, but there was still a lot of reluctance to actually decommission the old systems.
Recently we finally got the approval to turn off the old systems, and decommission the old HP-UX kit. When the change went through the Change Advisory Board (CAB) it was such a relief…
The kit is now decommissioned, and I’ve just been clearing the agents out of Cloud Control, so it’s finally over. No more HP-UX. No more Oracle 11g. No more Oracle Forms…
Now all we have to do is replace a whole load of Oracle Linux 7 servers, and get ready to upgrade to the next long term release of the database… 🙂
Please read the update before jumping to any conclusions. 🙂
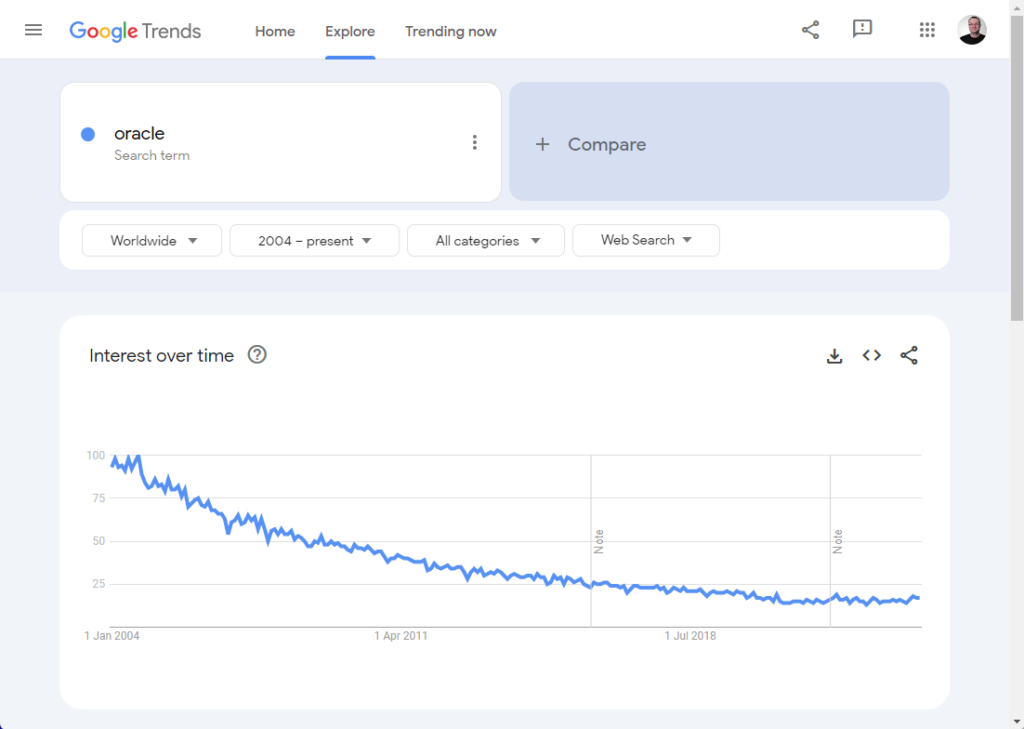
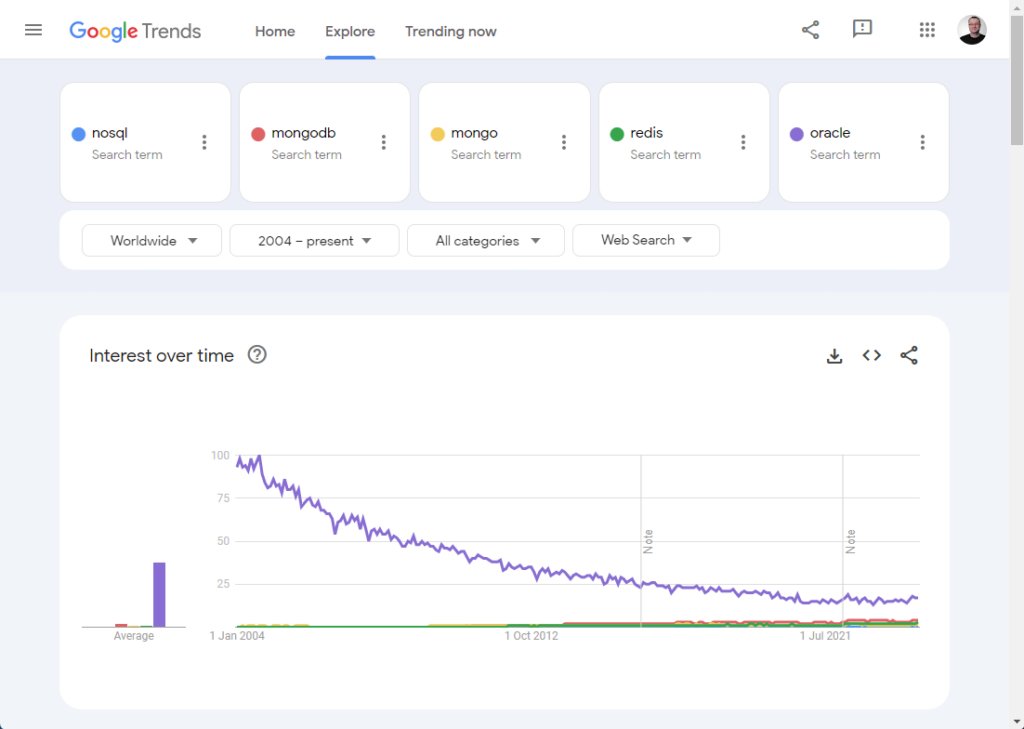
I was chatting with some folks the other day and the question was raised about if we had seen a decline in our website activity. Since the vast majority of my website traffic comes from Google searches, I figured the obvious thing to do was to look at what is happening on Google Trends in terms of search terms. That way we were not focusing on the popularity of a specific site, but on searches in general. That resulted in this rather alarming graph showing a trend over the last 20 years.
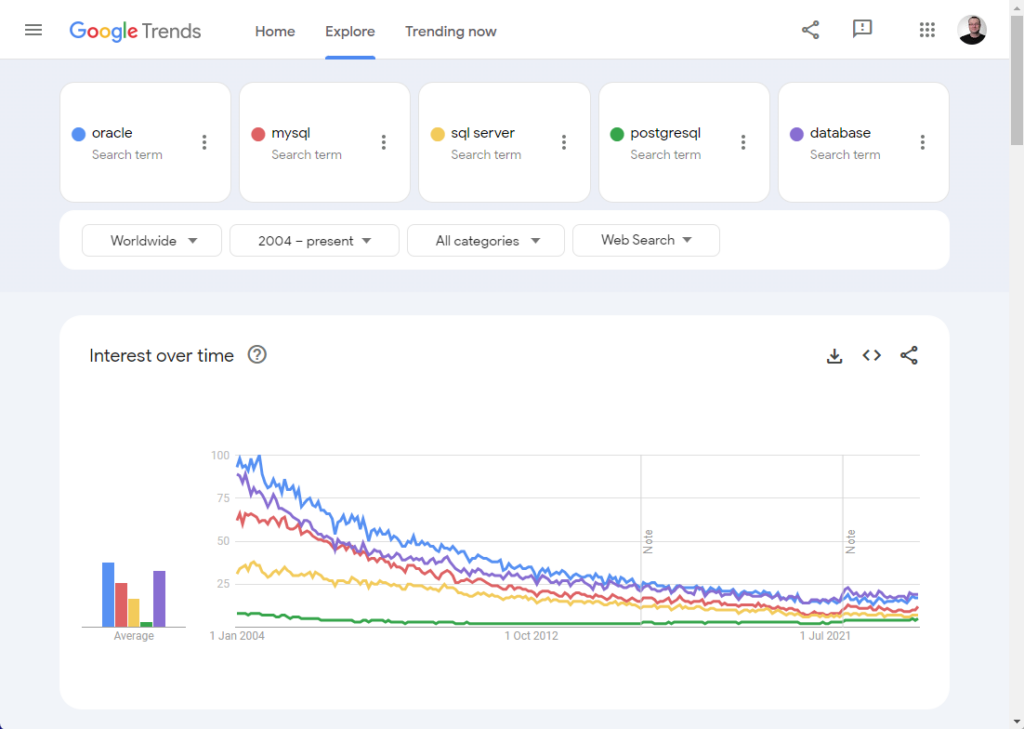
I guess we all thought this decline was at the expense of another engine, so our obvious next thought was to compare against the other relational database engines. One of the guys suggested we also compare the word “database” as well, just to see. This is the resulting graph.
It should be noted we tried variations on “sql server” and “postgresql”, but they didn’t affect the searches. Feel free to try for yourself. 🙂
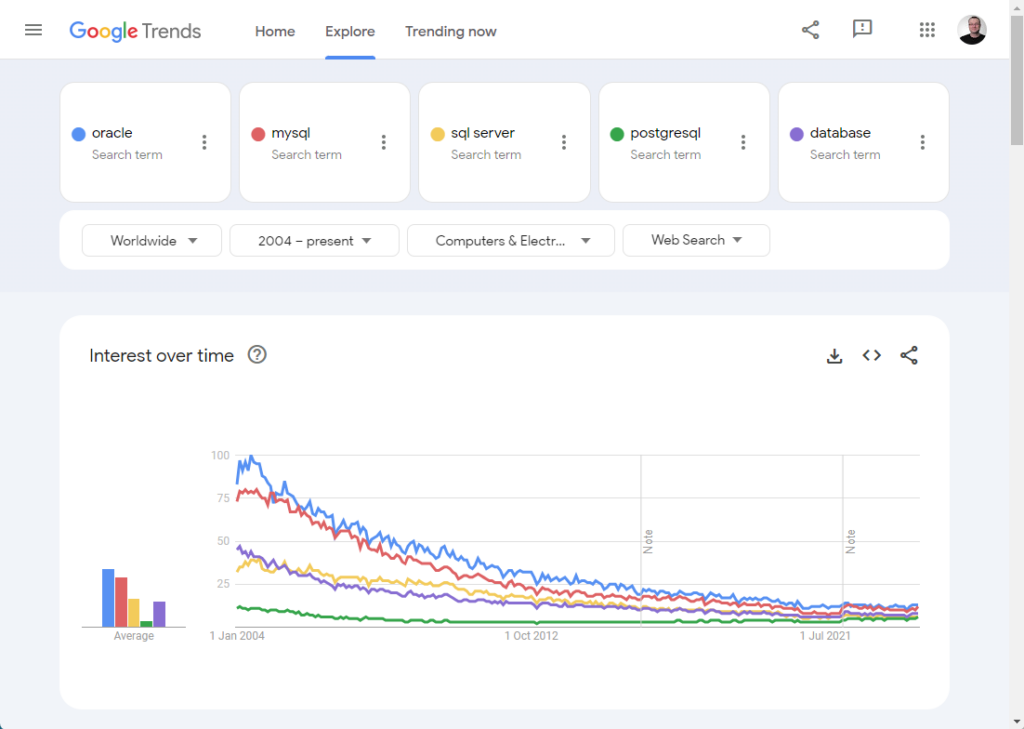
So the decline in searches was not restricted to Oracle. You may notice this is related to “All Categories” of search, and the word “oracle” is not specific to the database, so I tried in “Computers & Electronics”, and we got a similar result.
For subsequent searches I switched back to “All Categories”.
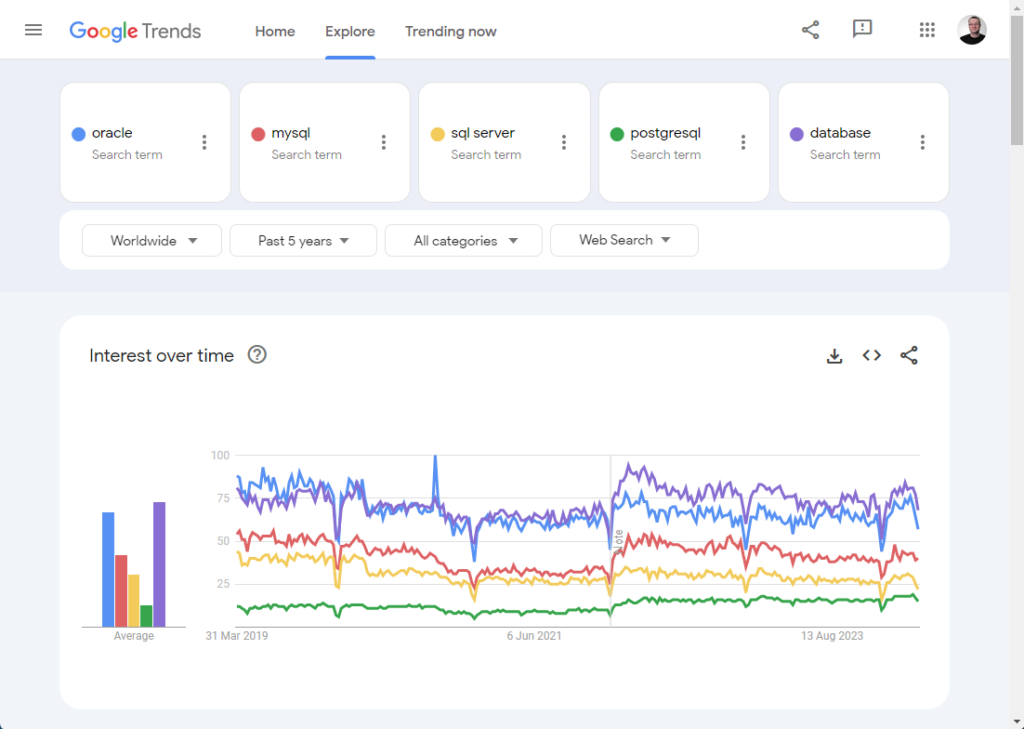
If we switch to the last 5 years, things seem to have levelled off somewhat.
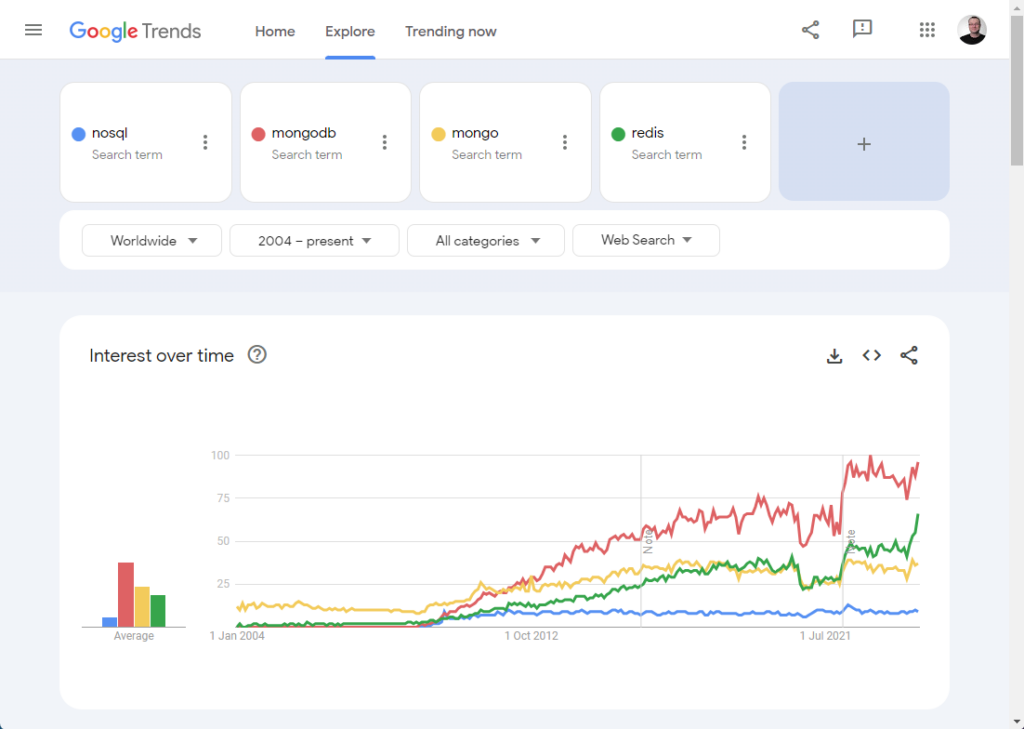
So the next question was if NoSQL databases were eating into the relational database market. A straight search looked interesting.
But what happens when we add Oracle back into the mix. Does the rise in popularity of some NoSQL databases account for the drop in searches for relational databases?
It doesn’t look like it. The gains in some NoSQL databases are insignificant compared to the reductions in searches for relational databases.
So we are left with a question. Why is there a drop off in searches for relational databases, when there doesn’t seem to be a corresponding uptick in alternatives?
Update : So what is really going on?
The graphs are not absolute search numbers, but normalised compared to the total Google searches that happened. Back in the day only geeks were Googling, so tech searches were a comparatively high percentage. Now everyone is Googling, the proportion of tech searches is much lower compared to the random stuff. Check out the FAQ about Google Trends data. So in our case, the trend over time of an individual term is not so important as the comparison between two search terms over time, as both should be affected in a similar way by the normalisation…
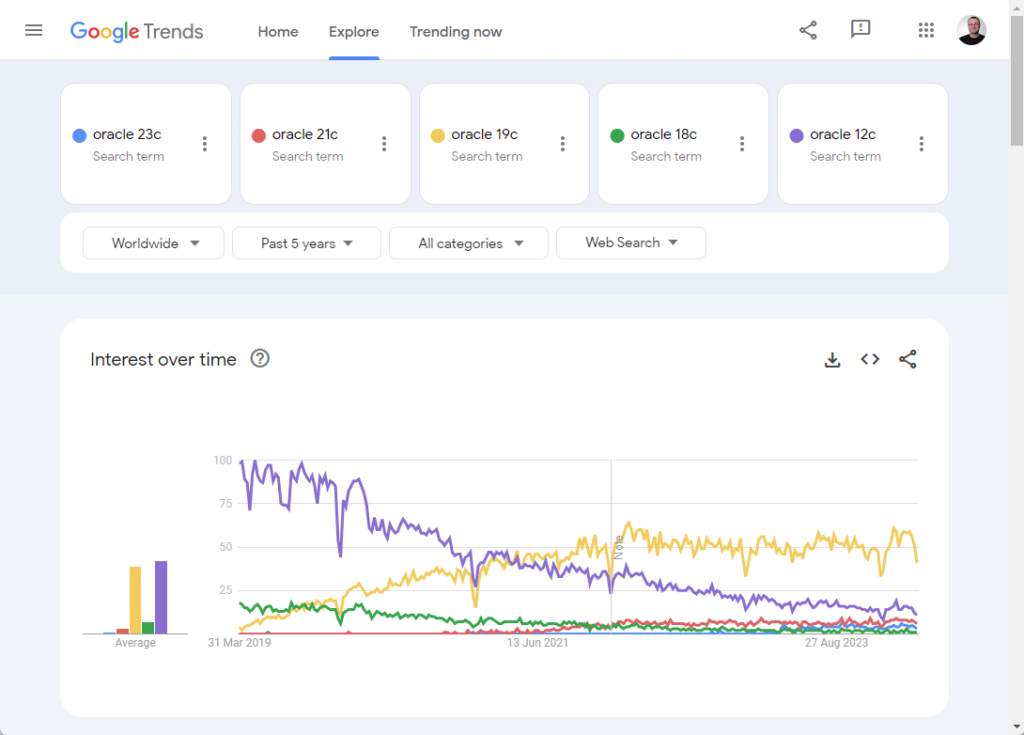
What we can see is over time the searches for different relational engines have got closer. If we are using the number of searches as a proxy for popularity, then it seems it’s a much closer game now than before.
Cheers
Tim…
PS. Thanks to the folks that pointed me in the right direction about Google Trends.
PPS. I noticed the switch from 12c to 19c searches over recent years.
Over the years I’ve extolled the virtues of Oracle Application Express (APEX) because of the ease of development. I think low code tools are a massive boon to productivity. Of course there are some tasks that need alternative tools, but for many scenarios low code tools are awesome.
Something else I find really appealing about APEX is the ease of upgrades. I’m not talking about how easy it is to apply the upgrade itself, because updating Java and Tomcat versions on a server is really easy too. I mean how simple it is from a wider perspective.
I was the first person in my company to use APEX. I used it to write some utility type applications, when it was still “forbidden”. Some of these applications were written over a decade ago, and they are still working fine. In that time we’ve had regular APEX upgrades, and they’ve just kept going. No refactoring. No drama.
Of course, they aren’t using all of the new features that were added in subsequent releases, but the important thing is all that development investment was not impacted by staying on the latest APEX release and patch set. In comparison, updating some of our other platforms and frameworks is a nightmare, requiring substantial development effort and testing.
So it’s not just about improving productivity during the development phase. It’s also about the reduction in the total cost of ownership (from a development perspective) over the lifespan of the application.
Just thought I would share that thought, as I upgrade & patch some production systems… 🙂
One of the points I made was we are having to replace OL7 servers, but were forced to go to OL8 because Oracle 19c was not certified on OL9, and Oracle 23c on-prem is not available.
This blog post by Mike DieTrich changed all that because now 19c is certified on OL9, provided you are on patch 19.19 or above, and are on the correct version of UEK or the RHEL kernel. See Mike’s post for details.
Installation Articles
Of course, this triggered some installation articles.
I noticed something a little odd when doing these builds using the 19.21 RU patches.
For the database and Data Guard builds I used the DB RU and OJVM combo patch, and I was still forced to fake the distribution using the CV_ASSUME_DISTID environment variable. For the RAC build I used the GI RU and OJVM combo patch, and I didn’t need to fake the distribution.
I went back to the DB build, and instead used the GI RU and OJVM combo patch, and I no longer needed to fake the distribution. So it looks like there is something different about the database patches between these two types of RUs that slightly affect the installation process. It’s no big deal, but it might catch you out.
Oracle 19c is old. Why do you care?
We are in the process of replacing a load of VMs that are currently running OL7, and we want to go to OL9. Prior to this announcement were were going to have to do one of two things.
Migrate to 19c on OL8, which would be OK for 23c when it drops, but not ideal as building an OL8 box now seems like a fail.
Wait for 23c on-prem to drop and move to 23c on OL9. The problem here is we could run out of time waiting for 23c to come.
This announcement gives us a new option.
Migrate to 19c on OL9, then upgrade to 23c when the on-prem version drops.
This third option is way better for us!
Remember
There are a couple of things to remember.
You need to be on 19c to upgrade to 23c, so getting your 19c database on an OS that is supported for 23c is important. We’ve had confirmation that 23c will be available for OL8 and OL9 on release.
The extended support waiver for 19c was increased from 1 year to 2 years. Mike also wrote about this here. That means you get free extended support for 19c until April 30, 2026.
Oracle Cloud World is happening, which typically means lots of announcements. One of the welcome announcement was the release of Oracle 23c on OCI Oracle Base Database Service, so there is a production version generally available… Sort of… Why do I say “sort of”?
OCI Oracle Base Database Service
This is a single cloud service, and it’s not available on the free tier, so it’s only available for paying customers that want to use this particular service.
At the time of writing there is no Autonomous Database service for this version, and there is still no full on-prem release.
I thought it was unavailable in my data centre, but Jeff Smith told me 23c GA is only available for Intel shapes at the moment. Once I switched from the default AMD shape to an Intel shape and 23c release was in the database version list. Happy days.
Oracle Database 23c Free
In addition to the OCI Oracle Base Database Service, the announcement post mentions a new version of Oracle Database 23c Free. It is now a “Developer Release”, not a “Developer Preview”. You can get hold of it here.
The slightly confusing thing is there is no difference in the file name, so my immediate impression was it had not actually been released yet. I downloaded the file and did an installation, and sure enough it was version 23.3. It would have been nice if there was an indication of the update on the page, or a version number in the file name…
For those that previously used Oracle XE, Oracle Database 23c Free is now the natural replacement, so go crazy with it. 🙂
The documentation links we’ve been using for 23c Free are no longer marked as “Free”. It is the normal GA documentation now.
My 23c Articles
You can see all my 23c articles here. There are still some I can’t publish until the on-prem GA release happens…
On-Prem Release
As mentioned previously, there is no full on-prem release for Oracle 23c, so you can’t start planning your upgrades from 19c yet. It’s really good to have an updated version of Oracle Database 23c Free so quickly for home use, but from a work perspective 23c won’t really exist for me until there is an on-prem release.
I’m hoping that won’t be long, but time will tell.
This is a very interesting development for a number of reasons. Here are some of my thoughts…
The database is not a driving factor in cloud provider selection
Over the years Oracle have been playing the game of making Oracle Cloud look like the most attractive place to run Oracle databases. What I think they had lost sight of is the database is not the driving factor in the choice of which cloud provider to pick. It might not even be part of the decision process. Quite often there are other factors that have much more sway.
This move is a welcome step, but I feel like it should just be the beginning!
Software should run on every cloud
I’m sure some people in Oracle now consider themselves a “cloud company”, but I think most of us still consider Oracle as a software company. Oracle rely on sales/licensing to make their money. As a result, anything that blocks the sale of a product is a problem.
Whatever cloud provider I pick, Oracle should be hoping I choose their software to run on my systems.
Not only are companies multi-cloud, but they already use multiple database engines. If there is any friction to using your product, they can go elsewhere.
A welcome start, but…
I’m really glad Oracle have taken this step. Microsoft are the second largest cloud provider, and anything that simplifies using Oracle databases on Azure is a good thing. IMHO this should be the start of the journey. Oracle should be trying to get similar partnerships with other cloud providers too.
Unless I’m missing something, or it’s not been amended yet, this document looks unchanged to me.
The pricing of Oracle on Azure seems to be unchanged, and we are still limited to AWS and Azure as “Authorized Cloud Environments”.
What would I do?
There are two main things:
I would make the pricing consistent across all cloud providers and on-prem.
I would increase the number of “Authorized Cloud Providers”.
The stats vary, but a quick Google shows me the following market share information.
AWS : 32%
Azure : 22%
Google : 11%
Alibaba : 4%
Oracle : 2%
Just adding Google and Alibaba would add another 15% of the cloud market as potential customers.
What do I know?
I’m sure someone will tell me I don’t know what I’m talking about, and maybe they are right. I just think Oracle should be making sure most/all of their software is available to run anywhere people want to run it.
As I said before, I’m really happy about this announcement, but I think it needs to be the first step on a longer journey.