In my previous post on this subject I mentioned the potential for human error in manual processes. This leads nicely into the subject of this post about reliability and confidence…
I’ve been presenting at conferences for over a decade. Right from the start I included live demos in those talks. For a couple of years I avoided them to make my life simpler, but I’ve moved back to them again as I feel in some cases showing something has a bigger impact than just saying it…
The Problem
One of the stressful things about live demos is they require something to run the demo on, and what happens if that’s not in the state you expect it to be?
I had an example of this a few years ago. I was in Bulgaria doing a talk about CloneDB and someone asked me a question at the end of the session, so I trashed my demo to allow me to show the answer to their question. I forgot to correct the situation, so when I came to do the same demo at UKOUG it went horribly wrong, which lead someone on Twitter to say “session clone db is a mess“, and they were correct. It was. The problem here was I wasn’t starting from a known state…
This is no different for us developers and DBAs out in the real world. When we are given some kit, we want to know it’s in a consistent state, but it might not be for a few reasons.
Human Error
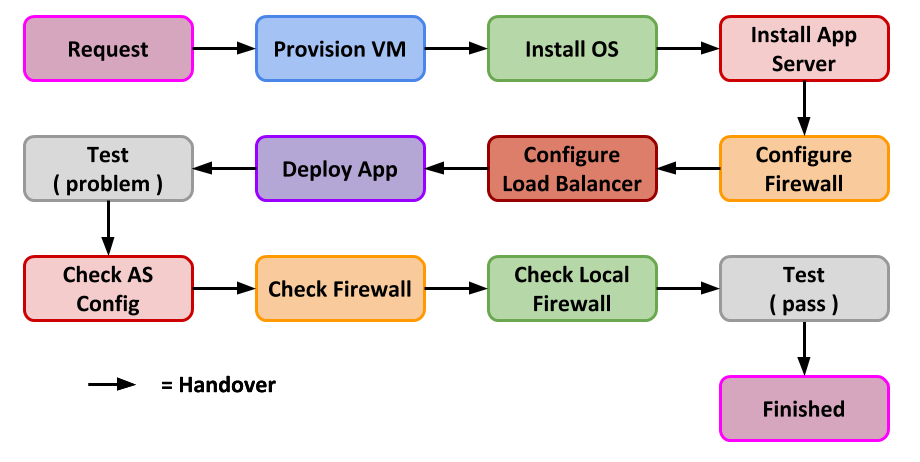
The system was created using a manual build process and someone made a mistake. I think almost every system coming out of a manual process has something screwed on it. I make mistakes like this too. The phone rings, you get distracted and you come back to the original task and you forget a step. You can minimise this with recipes and checklists, but we are human. We will goof up, regardless of the measures we put in place.
Sometimes it’s easy to find and fix the issue. Sometimes you have to step through the whole process again to identify the issue. For complex builds this can take a long time, and that’s all wasted time.
Changes During the Lifespan
The delivered system was perfect, but then it was changed during its lifespan. Here are a couple of examples.
App Server: Someone is diagnosing an issue and they change some app server parameters and forget to set them back. Those don’t fix the current issue, but they do affect the outcome of the next test. Having completed the testing successfully, the application gets moved to production and fails, because UAT and Live no longer have the same environment, so the outcomes are not comparable or predictable.
Database: Several developers are using a shared development database. Each person is trying to shape the data to fit their scenario, and in the process trashing someone else’s work. The shared database is only refreshed a handful of times a year, so these inconsistencies linger for a long time. If the setup of test data is not done carefully you can add logical corruptions to the data, making it no longer representative of a real situation. Once again the outcomes are not comparable or predicable.
The Solution?
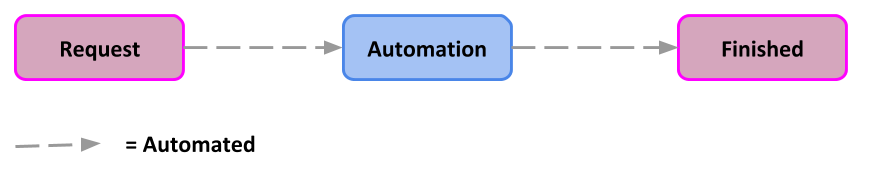
I guess from the title you already know this. Automation.
Going back to my demo problem again, I almost had a repeat of this scenario at Oracle Code: Bangalore a few months ago. I woke up the day of the conference and did a quick run through my demos and something wasn’t working. How did I solve it? I rebuilt everything. 🙂
I do most of my demos using Docker these days, even for non-Docker stuff. I use Oracle Linux 7 and UEK4 as my base OS and kernel, so I run Docker inside a VirtualBox VM. The added bonus is I get a consistent experience regardless of underlying host OS (Windows, macOS or Linux). So what did the rebuild involve? From my laptop I just ran these commands.
vagrant destroy -f
vagrant up
I subsequently connected to the resulting VM and ran this command to build and run the specific containers for my demo.
docker-compose up
What I was left with was a clean build in exactly the condition I needed it to be to do my demos. Now I’m not saying I wasn’t nervous, because not having working demos on the morning of the conference is a nerve wracking thing, but I knew I could get back to a steady state, so this whole issue resulted in one line in the blog post for that day. 🙂 Without automation I would be trying to find and fix the problem, or manually rebuilding everything under time pressure, which is a sure fire way to make mistakes.
I do some demos on Oracle Database Cloud Service too. When I recently switched between trial accounts my demo VM was lost, so I provisioned a new 18c DBaaS, uploaded a script and ran it. Setup complete.
Confidence
Automation is quicker. I think we all get that. Having a reliable build process means you have the confidence to throw stuff away and build clean at any point. Think about it.
- Developers replacing their whole infrastructure whenever they want. At a minimum once per sprint.
- Deployments to environments not just deploying code, but replacing the infrastructure with it.
- Environments fired up for a single purpose, maybe some automated QA or staff training, then destroyed.
- When something goes wrong in production, just replace it. You know it’s going to work because it did in all your other environments.
Having reliable automation brings with it a greater level of confidence in what you are delivering, so you can spend less time on unplanned work fixing stuff and focus more on delivering value to the business.
Tooling
The tooling you choose will depend a lot on what you are doing and what your preferences are. For example, if you are focusing on the RDBMS layer, it is unlikely you will choose Docker for anything other than little demos. For some 3rd party software it’s almost impossible to automate a build process, so you might use gold images as your starting point or partially automate the process. In some cases you might use the cloud to provide the automation for you. The tooling is less important than the mindset in my opinion.
Check out the rest of the series here.
Cheers
Tim…
 As always, I have to start with a warning.
As always, I have to start with a warning.




 There have been some stories recently about the death/deprecation of TLS 1.0 and 1.1. They follow a similar format to those of a few years ago about SSLv3. The obvious question is, should you panic? The answer is, as always, it depends!
There have been some stories recently about the death/deprecation of TLS 1.0 and 1.1. They follow a similar format to those of a few years ago about SSLv3. The obvious question is, should you panic? The answer is, as always, it depends!


 A couple of hours later I was at the station in Amersfoort waiting for the train to the airport where I was joined by
A couple of hours later I was at the station in Amersfoort waiting for the train to the airport where I was joined by  Once I got to the conference the day started with a keynote about “Autonomous Data Management” by
Once I got to the conference the day started with a keynote about “Autonomous Data Management” by  From there I went to see
From there I went to see  The next session I went to was “All about linux memory usage by the Oracle database” by
The next session I went to was “All about linux memory usage by the Oracle database” by From there it was off to “Kicking the Tyres on Oracle Database 18c with Swingbench” by
From there it was off to “Kicking the Tyres on Oracle Database 18c with Swingbench” by  After a quick closing ceremony, then some drinks and nibbles the conference was over.
After a quick closing ceremony, then some drinks and nibbles the conference was over.