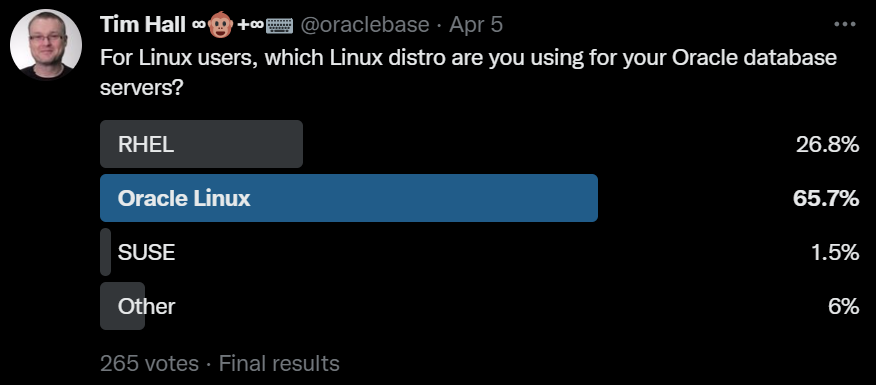
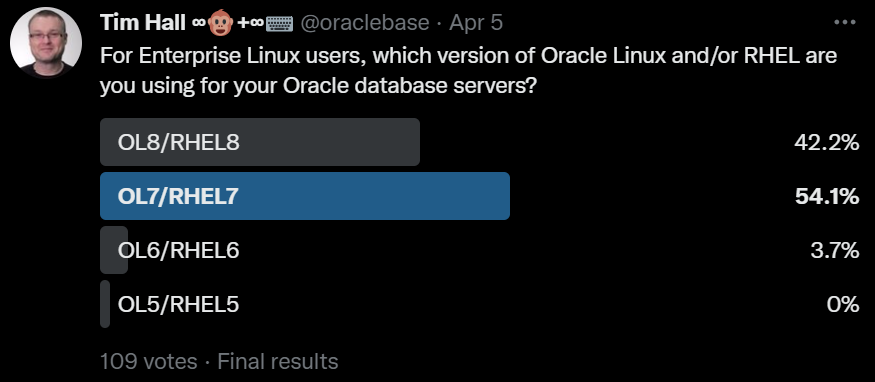
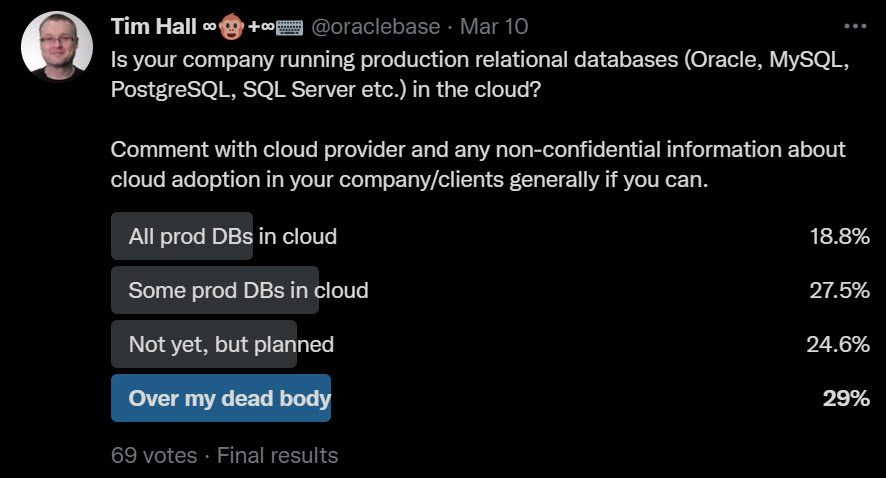
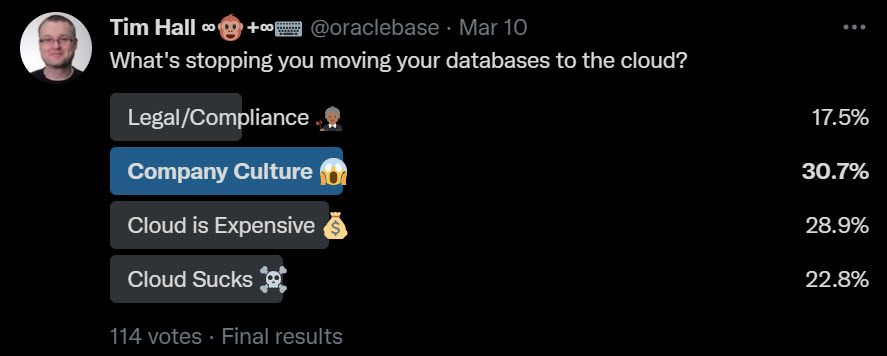
If you came hear hoping I was going to say there are valid reasons not to patch, you are out of luck. There is never a valid reason not to patch…
Instead this post is more about the general approach to patching. I’ve spent 22+ years writing about Oracle, including how to install it, but I’ve written practically nothing about how to patch a database. My stock answer is “read the patch notes”, and to be honest that is probably the best thing anyone can do. Although patching is a lot more standardized these days, it’s still worth reading the patch notes in case something unexpected happens. In this post I just want to talk about a few top-level things…
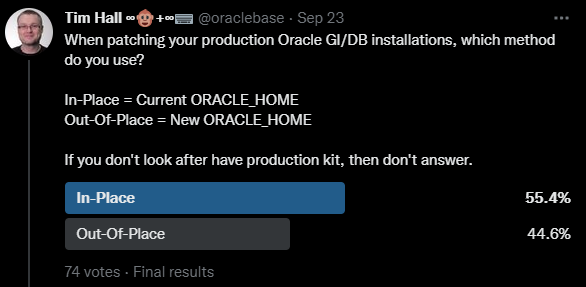
Patching to a new ORACLE_HOME
There are two big reasons for patching to a new ORACLE_HOME, or out-of-place patching.
- You can apply the binary patches to the new home while the database is still running in the old home, so you reduce the total amount of downtime.
- You have a natural fallback in the event of the wanting to revert the patch. You don’t have to wait for the patch rollback to complete.
There are some downsides though.
- It requires extra space to hold both the unpatched and patched homes, until you reach a point where you are happy to remove the unpatched home.
- If you have any scripts that reference the ORACLE_HOME, they will need to be updated. Hopefully you’ve centralized this into a single environment setup script.
- I guess it’s a little more complicated, and the patch notes are not that helpful.
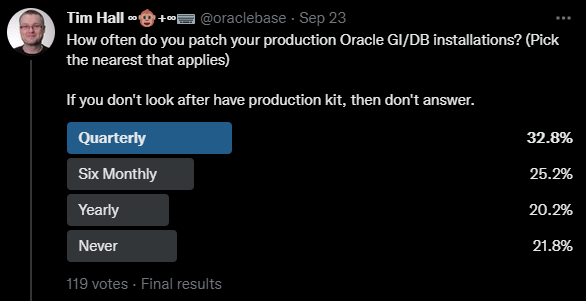
So should you follow the recommendation of patching to a new home or not? The answer as always is “it depends”.
The reduction in downtime for a single instance database is good, but if you are running RAC or Data Guard, this isn’t really an issue as the database remains online for most of the patching anyway. Having a quick fallback is great, but once again if you are running RAC or Data Guard this isn’t a big deal.
If you are running without RAC or Data Guard, you have made a decision that you can tolerate a certain level of downtime, so is taking the system down for an hour every quarter that big a deal? I’ve heard of folks who use RAC and/or Data Guard who still bring the whole system offline to patch, so the decision is probably going to be very different for people, depending on their environment and the constraints they are working with.
I hope you’re taking OS and database backups before patching. If something catastrophic happens, such that a rollback of the patch is not possible, you can recover your original home and database from the backups. Clearly this could take a long time, depending on how your backups are done, but the risk of loss is low. So the question is, can you tolerate the additional downtime?
You have to make a decision on the pros and cons of each approach for you, and of course deal with the consequences. If in doubt, go with the recommendation and patch to a new home.
Read-only Oracle homes
Read-only Oracle homes were introduced in 18c (here) as an option, and are the default from Oracle 21c onward. One of the benefits of read-only Oracle homes is they make switching homes so much easier. You haven’t got to worry about copying configuration files between homes, as they are already located outside the home.
Release Update (RU) or Release Update Revision (RUR)?
You have a choice between patching using a Release Update (RU), or a Release Update Revision (RUR). To put it simply, a RU contains not only the latest security patches and regression fixes, but may also include additional functionality, so the risk of introducing a new bug is higher. A RUR is just the security patches and regression fixes. Unlike the Critical Patch Updates (CPUs) of the past, that ran on endlessly, RURs are tied to specific RUs, so you will end up applying the RUs, but at a later date, when hopefully the bugs have been sorted by the RUR…
The folks at Oracle suggest applying the RUs, which is what I (currently) do. Some in the Oracle community suggest applying RURs is the safer strategy. If you look at the “Known Issues” for each RU, and the list of recommended one-off patches that should be applied after the RU, you can see why some people are nervous of going directly to RUs.
Once again, this comes down to you and your experience of patching with the feature set you use. If you are finding RUs are too problematic, go with the RUR approach. You can always change your mind at any time…
Monthly Recommended Patches (MRPs)
There’s a new kid on the block starting with 19.17 on Linux, which are monthly recommended patches (MRPs). They replace RURs. There are 6 MRPs per RU, with each MRP containing the RU and the current batch of recommended one-off patches, as documented in MOS Note 555.1.
I’m assuming these are rolling and standby-first patches, but I can’t confirm that yet.
RAC Patching : Rolling Patches
Rolling patches can be applied one node at a time, so there are always database instances running, which means the database remains available for the whole of the patching process.
Release Updates (RUs) and Release Update Revisions (RURs) are always rolling patches, so it makes sense to take advantage of this approach. If you are applying one-off patches, these may not be rolling patches, so always check the patch notes to make sure.
Even when rolling patches are available, you can still make the decision to take the whole system offline to apply the patches. I’m not sure why you would want to do this, but the option is there for you.
Data Guard : Standby-First Patches
Release Updates (RUs) and Release Update Revisions (RURs) are always standby-first patches. This gives you some flexibility on how you approach patching your system. Here are two scenarios with a two node Data Guard setup, where node 1 is the primary and node 2 is the standby.
Scenario 1 : Switchovers
- Patch the node 2 binaries (not datapatch) and bring the standby back into recovery mode.
- Switchover roles, making the node 2 the primary and node 1 the standby.
- Patch the node 1 binaries (not datapatch) and bring the standby back into recovery mode.
- Run datapatch against node 2 (the primary database).
- Optionally switchover roles making node 1 the primary database again.
Scenario 2 : No switchovers
- Patch the node 2 binaries (not datapatch), but don’t start the standby.
- Patch the node 1 binaries (not datapatch) and start the database.
- Start the standby on node 2.
- Run datapatch on node 1 (the primary).
Scenario 1 reduces downtime, as the primary is always running while the standby is having the binaries patched. Scenario 2 is simpler, but has a more extensive downtime as the primary is out of action while the binaries are being patched.
Remember, one-off patches may not be standby-first patches, so you may only have the option of scenario 2 when applying them. You have to read the patch notes.
OJVM Patching : Which approach?
Oracle 21c has simplified the OJVM patching situation. In previous releases the OJVM patches were completely separate. The grid infrastructure (GI) and database patches for 21c include the OJVM patches. For 19c the OJVM patches are still separate.
The separate 19c OJVM patches come with additional restrictions. They are not standby-first patches, and according to the patch notes, they can only be applied as RAC rolling patches if you use out-of-place patching.
Why don’t you write about patching much?
Writing about patching is difficult, because everyone has a unique environment, and their own constraints placed on them by their business. I’ve always avoided writing too much about patching because I know it’s opening myself up for criticism. Whatever you say, someone will always disagree because of their unique situation, or demand yet another patching scenario because of their unique environment. You’re damned if you do, and damned if you don’t.
I’ve recently written a few patching articles for specific scenarios (here). I may add some more, but it’s not going to be a complete list, and don’t expect me to write articles about stuff I don’t use, like Exadata. These are purely meant as inspiration for new people. Ultimately, you need to read the patch notes and decide what is best for you!
Let the cloud do it!
If all this is too much hassle, you do have the option of moving your database to the cloud and letting them worry about patching it. 🙂
Conclusion
Read the patch notes!
Cheers
Tim…