A combined 5 years as an Oracle Developer Champion, renamed to Oracle Groundbreaker Ambassador. (21 June 2017) This will be the last time I mention this, as the Groundbreaker Ambassador is now being merged back into the ACE program. It was fun while it lasted. 🙂
OpenWorld and Code One 2019 are over, and here are a few thoughts…
The tech side of things was based almost exclusively at Moscone South this year. No walking around to different buildings and hotels. In part that was due to the Moscone rebuild, making it a much larger venue now, but I suspect the numbers were down a lot on previous years. It’s hard to know as wider corridors mean you are less packed in, so maybe it was an optical illusion…
The conference felt more like a tech event this year, and less like a marketing event. OpenWorld and Code One were a lot more joined up, and I would suggest this year it was actually a single conference. I’m sure the split branding will remain for political reasons, but it would make life a lot easier if it were one event with one session catalog.
The new branding for Oracle was interesting. I said in a previous post I liked it. Much softer than the old red stuff. Let’s see how people react to it, and let’s see if the company actually changes to be more customer focused. I wrote a post called Oracle: Tech Company or Service Company? a few years ago. Maybe Oracle are now catching up? We’ll see.
The VMware announcement was interesting. I expressed my opinion on this here. I just hope this isn’t short-lived and I hope sense prevails. Oracle need to build bridges now. It’s still possible. Remember when everybody hated Microsoft?
Obviously Oracle continued to push Cloud and the Autonomous brand, including the new Autonomous Linux and Autonomous JSON. If you’ve used SODA, you know what’s going on with Autonomous JSON. From my perspective, keep the autonomous services coming. The more automated the mundane stuff becomes, the better!
For many database people, the big news items were:
3 PDBs in 19c and desupport of non-CDB in 20c (discussed here)
Free Tier : At last, something more than the 30 second free trial. I hope people make use of this and give plenty of feedback to Oracle!
Overall, it was a cool, fun, weird, stressful, tiring week. Part of me thinks this might be my last OpenWorld, but I said that after my first one, and I’ve now been to 14…
The posts I put out during the event were as follows.
I got up at a reasonable time and got caught up with blog posts, then it was time to check out and get the BART to the airport. Bag drop was empty, because the rest of the planet was waiting at security. After what felt like an eternity I was through security and sat down and waited for my plane…
We boarded the flight from San Francisco to Amsterdam on time and didn’t have a significant wait for the departure slot, so the captain said we would arrive early. No luck with a spare seat on this flight. The guy next to me was about my size, but wasn’t making an effort to stay in his space. There was some serious man-spreading going on. I ended up spending most of the flight leaning into the aisle and pulling my arm across my body, so my left elbow feels knackered now. Doing that for 11 hours is not fun. I managed to watch the following films.
Rocketman – I wasn’t feeling this at the start. I’m not big on musicals, and I didn’t like the stuff when he was a kid. Once Taron Egerton started playing him it was cool. I kind-of forgot he wasn’t Elton John. If you can get past the start, it’s worth a go!
The Accountant – I liked it. Ben Affleck doing deadpan and expressionless is the perfect role for him.
John Wick: Chapter 3 – Parabellum – I got up to the final sequence, so I’m not sure how it ends. Pretty much the same as the previous films, which I liked. Just crazy fight scenes with loads of guns.
There was one bit of the flight that was odd. The in-flight entertainment died, then we hit some turbulence. Queue me deciding it was linked and we were all going to die… Pretty soon the turbulence stopped, then after about 10 minutes the screens rebooted…
I had quite a long wait at Schiphol. About 3 hours. That was pretty dull, but what are you going to do?
The flight from Amsterdam to Birmingham was delayed by a few minutes, then the was the issue of people trying to board with 15 pieces of hand luggage and a donkey. I had my bag on my feet. Luckily it was only an hour flight.
II was originally planning to get the train home, but I was so tired I got a taxi. The driver was a nice guy and we had a chat about his kids and future plans, which is a lot nicer than listening to me drone on…
I’m now home and started doing the washing…
I’ll do a wrap-up post tomorrow, with some thoughts about the event…
I started Wednesday by trying to play catch-up with some of the keynotes. I don’t like going to them, but it’s important to hear what was said, because people often put their own spin on what was actually said to make it fit with their narrative.
From there I headed down to the conference to see Michael Hüttermann with “DevOps: State of the Union”. Michael managed to pull off a session where we did all the talking. How does that work? 🙂 It was really good fun, and it was interesting to hear other people’s experiences, and how they define DevOps.
Next up was Simon Coter with “Practical DevOps with Linux, Virtualization, and Oracle Application Express. At the start of the session Simon started a Vagrant build using the “vagrant up” command, then continued with the session, describing how tools such as VirtualBox and Vagrant can help you build consistent environments. He then described this specific build and showed us the finished product. I think the session went really well, and if you follow the blog you know I’m a VirtualBox+Vagrant fan. The other thing worth mentioning was he showed how a VirtualBox VM can be exported to OCI, and maybe in future an OCI VM imported back into VirtualBox. The first of those two operations means you could use VirtualBox and Vagrant as your choice for custom infrastructure builds for the cloud. Interesting…
Next up was “Embracing Constant Technical Innovation in Our Daily Life”, which was a panel session made up of Gustavo Gonzalez, Sven Bernhardt, Debra Lilley, Francisco Munoz Alvarez and Me. We didn’t have a big crowd, but we did get some crowd participation. I find panels fun, and some of the practical suggestions included.
Write stuff, and preferably put it out on the internet. Thinking someone might read it makes you up your game, and something like blogging can help some people with motivation to try out new stuff. (Writing Tips)
Do presentations, because of the pressure of a deadline often makes you focus, and there is also a desire to present something new. Remember, presenting is not just about conferences. Get a group of people in your office and present stuff to the group. It’s a good skill to develop, improves your confidence and makes you more visible in the company and of course improves knowledge transfer! (Public Speaking Tips)
When you get good at one thing, it makes it easier to learn new things. You understand the effort it takes and you know you have to look below the surface. (Learning New Things)
Get involved with the community. A wise person learns by other people’s mistakes. Go to local meetups for subjects outside your main skill set, to give you a different perspective. It might reinforce your beliefs or challenge them.
After that it was off to see “Understanding the Oracle Linux Cloud Native Environment (OLCNE)” with Wiekus Beukes, Tom Cocozzello and Thomas Tanaka. Oracle have built a tool that allows you to install, manage and upgrade selected Cloud Native Computing Foundation projects. That tool is called OLCNE. Why is this important? Because there are loads of CNCF projects, with a load of dependencies, so trying to install, and more importantly upgrade them, can be a nightmare. This tool will make that easier, as it will manage dependencies, and keep track of which versions of project X are certified with which versions of project Y. All these versions will be tested by Oracle to make sure things just work. The idea being you want Kubernetes + CRI-O + Prometheus + Istio? Sorted. For someone like me, who is a complete noob at most of this, that is a really interesting proposition. The project will be open sourced and on GitHub. Once it gets enough non-Oracle people contributing to the project, they hope to submit it to CNCF. Maybe we are seeing the start of how to manage CNCF projects in the future?? 🙂
After that I went to see Colm Divilly speaking about “Database Management REST APIs”. The management APIs were introduced a couple of versions ago, but with each release they are adding more stuff. We now have integration with the DBCA for instance and PDB lifecycle management, as well as APIs to control features like Data Pump and get performance monitoring information. I really need to spend some time paying with these, because it’s a great way to automate operations and make them available to other people. I like to think of it as breaking down the walls of the silo by presenting what you do as a service.
Once that session was over I spent a few minutes talking to the ORDS and SQL Dev folks, then it was back to my hotel to crash. I ducked out of the concert (the ticket went to a good home) and other invites because I am old and my bed was calling me.
That was my last day at OpenWorld. I leave Thursday morning US time and will be back home at some point on Friday UK time. I’ll no doubt do a post about the journey home and a wrap-up post once I get back.
I was originally expecting to start Tuesday with the Cloud Native hands-on-lab, but it clashed with some other non-conference stuff I had scheduled, so I had to drop out of that. I played catch-up on blog posts and upgraded VirtualBox right before my demo, then went out to a photo shoot. Yes, I’m a model…
I had to get some shots done for a magazine piece, so Oracle arranged for me to meet a photographer and I spent some time looking off into the distance in a contemplative manner. I was going to say, “proper executive stuff”, but I was in a T-shirt and combats, so I looked my normal scruffy self. I’ve asked him to photoshop the hell out of them. If I’m recognisable, I won’t be happy. 🙂 I’m not normally at home in front of a camera, but it was surprisingly good fun. On Monday I spent 3 hours running crowd control for the photographer in the Groundbreakers Hub. On Tuesday I’m in front of the camera. I guess by Wednesday I’ll be running a production company…
From there I went straight to my “The 7 Deadly Sins of SQL” session. It covers things that are already on my website, but I’ll write a post specifically about it when I get home. I was surprised how many people showed up. It was a pretty full room. A few empty seats, but a few people standing at the back. The session clashed with the keynote, and a bunch of other sessions I would happily have attended if I wasn’t speaking, so I expected low numbers. Thanks to everyone who came. I hope you got something out of it.
I bumped into Don Sullivan from VMware and chatted to him about the impact of the Oracle & VMware announcement. Since the announcement of VMware Cloud Foundation on Oracle Cloud Infrastructure I’ve already seen some people write, “Oracle is now supported on VMware”, which makes me mad, as it has been supported for a looooong time. Plenty of people run Oracle tech on VMware and never get any problems accessing support. I’m one of those people. If nothing else, the announcement from Oracle will finally kill the Fear Uncertainty and Doubt (FUD) around this subject. The announcement does allow Oracle to take a piece of the pie as far a running VMware on the cloud, since VMware have already got all the other major players in the bag. I think this hybrid cloud approach will help many companies start their journey to the cloud, regardless of the cloud provider they pick to do it with.
From there I moved on to watch “The State of the Penguin” by Wim CoeKaerts, which is his yearly review of what’s happening in Linux and Virtualisation at Oracle.
If you’ve watched any of the announcements, I guess you know that Autonomous Linux was announced. I’m going to miss out a bunch of stuff for sure, but some interesting points coming out of this presentation were.
UEK6 is on the way, and will bring UEK to Oracle Linux 8 (OL8) for the first time.
The new Exadata X8M, which has the PMEM and RoCE stuff is shipping with KVM. The existing stuff and non-RoCE stuff is still shipping with the Xen hypervisor, but the future for Oracle’s visualisation thrust is KVM. If anyone is starting something new and thinking of picking the Xen-based OVM, you should probably not. 🙂
For ages Ksplice has been available to folks running Oracle Linux in the Oracle Cloud, as the license is baked in. This is now also the case when running Oracle Linux in Azure.
The plan is to make much of the Autonomous Linux stuff available for on-prem customers too. Wim repeatedly stated, what you have on-prem is what they run in the Oracle Cloud, and what you run in Azure etc. Most of their work is on upstream Linux, rather than on their own proprietary stuff, so everyone benefits from Oracle’s OSS contributions.
They are working on some stuff to simplify the setup and management of Kubernetes. It will be open sourced and accept community contributions once it goes to GitHub.
After that session I headed down to the Groundbreaker Hub and just hung around chatting to people. I also did a 60 second Periscope, which is much scarier than a 45 minute presentation. 🙂
This was the first evening I had free. I stuck by my guns and said no to every offer. I went back to my room and crashed! Tomorrow (Wednesday) is my last day at the conference, as I leave on Thursday morning…
When I get home I’ll probably write a series of posts about the Free Tier stuff. I’ve already written about many of the components included in the Free Tier offering individually (ADW, ATP, OCI Compute etc.), along with the supporting stuff (Compartments, Virtual Cloud Networks (VCNs), Firewall stuff etc.), but it would be good to give it a consistent story for people who are fresh into Oracle Cloud, even if it’s just links to what I already have, with some updated screen shots. I’ll sign up with a new account and go through it all from scratch.
I’ve had a number of discussions about the new Oracle branding, which is a lot softer than the previous branding and almost devoid of red. It’s been mostly positive, but one comment that keeps coming up is something along the lines of, “The new branding is supposed to be more customer focused, but that’s not going to go very far if the attitude of “the business” doesn’t change!” I think you know what that means, and I have to agree. Most people don’t have an issue the tech side of Oracle, but do have a big problem trusting the business side of Oracle. Let’s hope this branding change is the beginning of a new era on the business side of things too!
I was tempted to call this “Day 1”, because it’s day 1 of the main conference, but I’ve already had two very full days with very little sleep.
The day started with a walk down to Moscone, where I got my first surprise.
This is my 14th visit to OpenWorld and I’ve never seen this road open during the conference. I’m sure this made the locals a lot happier, as there were less traffic issues, but it did restrict the flow of people somewhat. Having said that, the finished Moscone rebuild means things are a lot more centralised this year, so that wasn’t such a big deal for me.
I started off with a walk around the demo grounds, where I saw some familiar folks. Thank you Dbvisit for something familiar in sea of changes around the conference. 🙂
I also saw Connor MacDonald drawing a crowd at one of the “theatres” in the demo grounds. You can barely see the people sitting, because of the people standing around…
I stalked bumped into Wim Coekaerts in the demo grounds and had a fanboy moment chat with him about the move from Xen to KVM that has been happening. I’ll no doubt be at some of the Oracle Linux stuff over the remainder of the conference.
I chatted to John Beresniewicz for a while, which is always a pleasure. I bumped into Richard Foote, and we went to get some food and check out where our rooms were for presentations during the week. With the Moscone rebuild, it’s worth finding your feet early. Eventually I had to leave him, as he was constantly mobbed by people mistaking him for David Bowie. We also saw this…
Gone are the days of scantily clad “promo girls”. Now you get people to your stand by having a pen full of puppies. Everyone standing around thinking, “Tech or puppies? Food or puppies? Autonomous something or puppies?” I guess you know what won… 🙂 This was only one section of the pen. There were a lot of them, and I believe they were already adopted with good homes to go to, so I’ll forgive this exploitation. 🙂 I assume based on the results, next year’s OpenWorld and Code One event will morph into a dog show. You gotta do what pulls in the punters. 🙂
I booked in for a shift at the Groundbreakers Hub. I was meant to do 14:30 to 17:00, but I ended up starting early and finishing late, so most of my afternoon was playing at being a bouncer for the photographers doing head-shots for the speakers and members of the assorted community projects at the event. Really it was just an excuse to stand and chat to people. 🙂
As a result of my shift, I missed the keynote, so I’ll have to catch the recording of that, but I already knew most of the announcements, as would anyone paying attention to the exhibits around the conference. These were on the monitors before the announcements.
Now I wonder what one of the announcements was??? 🙂
Once my shift was over, I headed back to the hotel, then met up with some folks for dinner. I was once again the walking dead by that time, so I just slurred my way through the conversation. It was a good evening though! 🙂
Tomorrow (today by the time I post this) is my first presentation…
The ACE Director Briefing is under NDA, so I can’t talk about it. Most of the stuff mentioned will be known to the general public by the end of OpenWorld, so I’m not going to say anything here, as I don’t need the grief of saying something I shouldn’t. 🙂
The announcements are nice, and I think some people will be pleasantly surprised,but if I’m honest, the main thing for me is meeting everyone, including the wife and kids, who I’ve not seen for ages. There are a lot of people I only get to meet at these briefings each year…
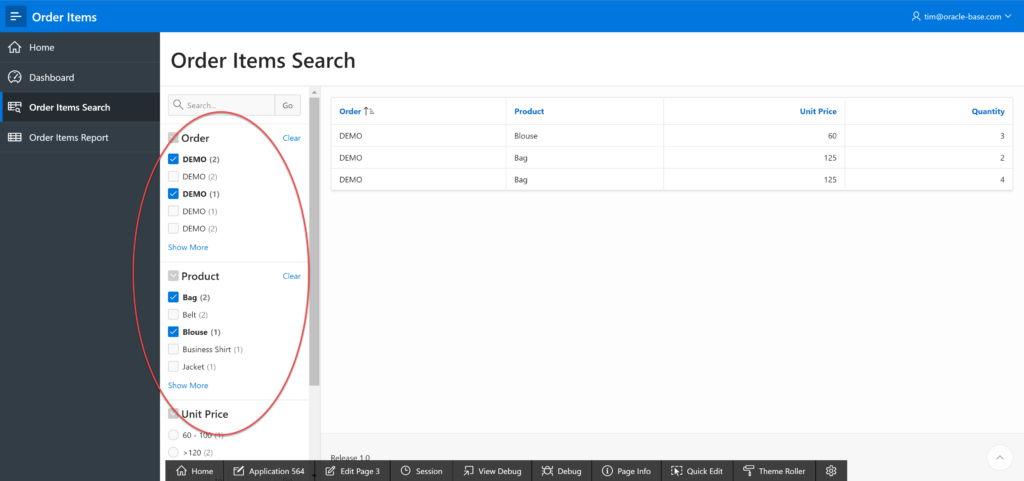
A thing that is definitely OK for us to talk about is APEX 19.2 EA, available at the following URL.
A number of features were discussed and demonstrated by Mike Hichwa and Joel Kallman, including a very impressive demo of the “Faceted Search” feature in APEX 19.2, which is just a few clicks away…
Navigate to “SQL Workshop”.
Use the “Object Browser”.
Click on table of interest.
Under the default “Table” tab, Click the “Create App” button.
On the subsequent screen, click the “Create App” button.
Accept the default app by clicking the “Create Application” button.
Click the “Run Application” button.
Click on the “{Table Name} Search” page.
Boom! You have Faceted Search.
And what you get out of the box looks like this…
Awesome! There is of course a Faceted Search page type for adding one to an existing application. APEX is a crazy good development tool these days!
After the briefing was done I went across to my Dad’s place to have a belated Birthday party. It was great to hook up again. Good food. Good company. It was a really nice end to the evening. Thanks Dad! I know he’s got a discoverer pass for OOW, so maybe we’ll get to see him around???
Cheers
Tim…
PS. As always, sleep continues to elude me, so I looks and feel like the walking dead! 🙂
The day began at 03:00, or more accurately it began the previous morning, as I didn’t sleep overnight. Normal nervous can’t sleep stuff.
I got a taxi to the airport, which was easy at that time. The first flight from Birmingham to Amsterdam was a little late to get going, but we played catch-up in the air. I got to Amsterdam, and the next boarding gate was close, so no drama there. At the boarding gate I met Frits Hoogland and Sai Penumuru, so we had a chat before the next flight from Amsterdam to San Francisco.
I got really lucky because I was in an aisle seat, and the middle seat was free. It felt like poverty business class. 🙂 The flight was long and boring, as you would expect, but I did get to watch the following.
Avengers: Endgame – It was a pretty good ride. I’m not sure it was deserving of all the hype, but it was good. There were a few scenes I loved. Seeing Valkarie on a flying horse was awesome. There was one scene where the most boring avenger did something I really liked.
Glass – I liked this, but if I’m honest I was expecting more, considering I loved both Unbreakable and Split.
We landed in San Francisco on time, but there was a long wait at customs. We eventually got through and took the BART to the city centre. From there it was a quick walk to the hotel. I checked in and went to bed to get a little sleep. A bit later I got up to go to the Oracle Groundbreakers dinner, then it was an early night, trying to play catch-up on lost sleep.
Today is the Oracle ACE Directors briefing…
Cheers
Tim…
Update 1: I was just told off for not mentioning “the wife”, even though I didn’t see her yesterday. To get me out of the dog-house, this morning I saw Debra Lilley…
Update 2: I was just told off for not mentioning “the daughter” and “the son”. At the Groundbreakers Dinner I got to meet with with my “problem child” daughter Heli, and my low maintenance son Gerald, who doesn’t tell me off if I don’t mention him… 🙂
Yesterday I went to Birmingham City University (BCU) to do a talk on “Graduate Employability” to a bunch of second year undergraduate IT students. I’ve done this a few times at BCU, and also at UKOUG for a session directed at students.
The session is what originally inspired the my series of blog posts called What Employers Want.
I’ve mentioned before, these sessions are a little different to your typical conference sessions. Perhaps you should try reaching out to a local college or university to see if they need some guest speakers, and try something outside your comfort zone.
Thanks to Jagdev Bhogal and BCU for inviting me again. See you again soon.
I woke up at 02:00. I tried to got back to sleep, but by a little after 03:00 I gave up and got out of bed. I hit the gym for a while, but felt pretty dreadful.
I mentioned yesterday, I had helped some people with setting up Oracle Cloud. Since I was awake I grabbed some screen shots and wrote a couple of small posts so I could forward them to one of the folks, so they could remember what we did. These along with a couple of other posts I released a few days ago pretty much show how we set up a demo environment in a few minutes..
Pretty soon it was time to go down to the Oracle ACE Director Briefing…
Like yesterday, the meeting was covered by a Non-Disclosure Agreement (NDA), so there isn’t really anything I can say about it, but during the briefing we were told Oracle Database 18c Express Edition (XE) had been released for download. I had previously done an 18c RPM installation on Vagrant, so it was pretty simple to modify it to do the XE installation in a similar way and leave it going while I was watching the sessions. Yay! Go automation! 🙂
I did my thing of not eating again, so I could stay awake during the meeting. By the end of the last session I felt pretty hungry, so I picked up a bag of cheese flavoured popcorn and downed that before heading to Chipotle (again). I think I’m done with Chipotle now. My vegetarian burrito had a huge chunk of meat in it, which I bit into and spat out. If it had been at the start of I would have demanded a new one, but as I had nearly finished I just walked up to the counter and said, “This is a vegetarian burrito and that is meat. Sort yourself out!”, then left in a bad mood.
I got back to the hotel and had about an hour before 19:00, when I was meant to go and meet people at some place about a block down the road. I made the fatal mistake of lying on the bed to watch TV for a bit, and waking up at 04:00 the next day. Sorry folks! 🙁 The fact I slept for about 10 hours, which is extremely rare for me, kind-of shows you were I was at by this point. 🙂
So that’s the first two days of briefings done. Tomorrow (today by the time you read this) is a “day off”, but I do have an event in the middle of the day and a dinner in the evening. I’ve also got to go through my three (and a bit) talks, because once the conference starts, there’s no telling when I will get time…
Cheers
Tim…
PS. I was forced to “disappear” Maria Colgan from the family because she came into the room and didn’t come immediately to say hello to me. If she is really good, and I don’t replace her with someone else, she may be allowed back into the family at some point in the future… 🙂

















 Yesterday I went to
Yesterday I went to  I woke up at 02:00. I tried to got back to sleep, but by a little after 03:00 I gave up and got out of bed. I hit the gym for a while, but felt pretty dreadful.
I woke up at 02:00. I tried to got back to sleep, but by a little after 03:00 I gave up and got out of bed. I hit the gym for a while, but felt pretty dreadful.