I’ve been thinking about my DBA and PL/SQL tool choices recently, so I thought I would go out to Twitter and ask the masses what they are using.
As always, the sample size is small and my followers have an Oracle bias, so you can decide how representative you think these number are…
Here was the first question.
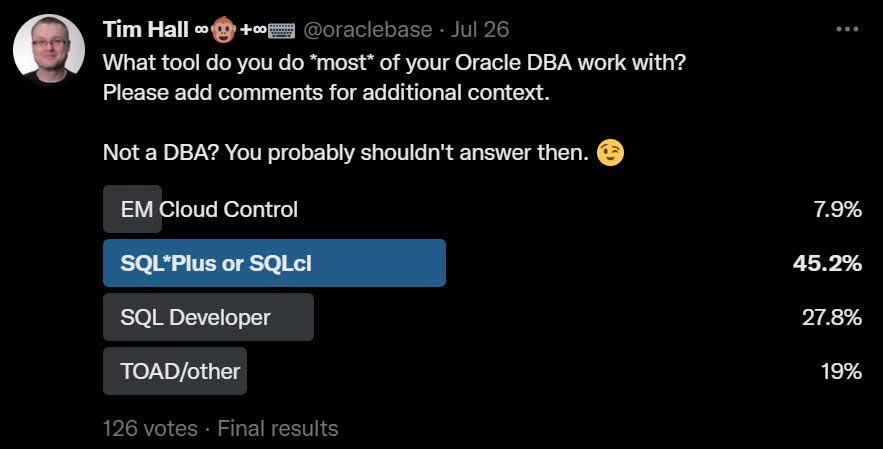
I expected SQL*Plus and SQLcl to be the winner here, and I was right. A lot of DBAs are still “old school” where administration is concerned. It may be tough for a beginner to use these command line tools, but over time you build up a list of scripts that mean it is much quicker than using GUI tools for most jobs.
SQL Developer had a pretty good showing at nearly 28%. I’m glad people are finding value in the DBA side of SQL Developer. TOAD/other were not doing so well. I know there are a lot of companies out there trying to make money with DBA tools, but maybe this is a tough market for them. Of course there are cross platform tools that may do well with other engines, even though they don’t register so well with the Oracle crowd.
I guess the real surprise was less than 8% using EM Cloud Control. Having said that, I’m considering ditching it myself. I like the performance pages and we use it as a centralized scheduler for backups, but I’m not sure our usage justifies the crazy bloat that is Cloud Control. It would be nice to remove all those agents and clean up! This figure of less than 8% is all the more surprising when you consider it is free (no cost option). Of course total cost of ownership is not just about the price tag…
This was the next question.
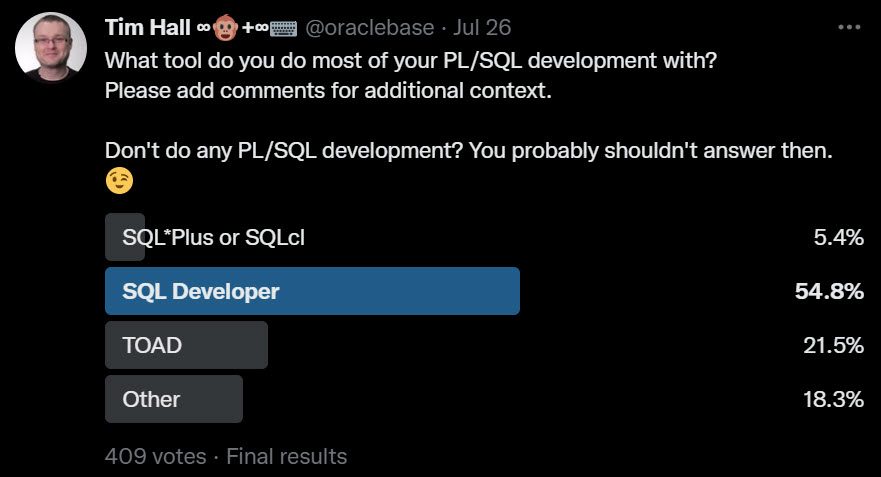
I was expecting SQL Developer to do well here, but I was surprised by how low TOAD was in the list. I’ve worked at a few companies over the years where TOAD was a staple. I guess the consistent improvements to SQL Developer and a price tag of “free” have broken the TOAD strangle hold.
There were a few comments about Allround Aautomations PL/SQL Developer, which I used in one company many years ago. If I could have added an extra line in the poll, I would have put that as an option, because I know it is still popular. There were also mentions of DataGrip and a number of people using VS code with assorted extensions, including Oracle Developer Tools for VS Code.
Sadly, but understandably, SQL*Plus and SQLcl were low on this list. I’m an old timer, so I’ve had jobs where this was the only option. At one job I wrote my own editor in Visual Basic, then rewrote it in Java. Once SQL Developer (known as Raptor at the time) was released I stopped working on my editor…
When you’re doing “proper” PL/SQL development, it’s hard not to use an IDE. They just come with so much cool stuff to make you more productive. These days I tend to mostly write little utilities, or support other coders, so I find myself writing scripts in UltraEdit and compiling them in SQLcl. If I went back to hard core PL/SQL development, I would use an IDE though…
For fun I ended with this question.
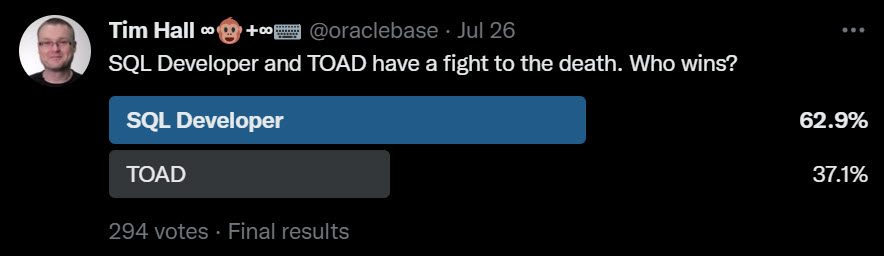
SQL Developer won, but it came out with a detached retina and some broken ribs!
Remember, you are most productive using the tools that suit your working style, but you should always keep your eyes open for better ways of working. Choice is a wonderful thing!
Cheers
Tim…