Yesterday I tweeted that I was reminded of this post.
I was reminded of it because of something that is happening to me at work, so I thought I would talk about it here.
Production lines
If you’ve read anything about DevOps you will know it came from manufacturing. If you didn’t know that, check out The Goal, which was the basis for The Phoenix Project.
Manufacturing typically uses production lines made up of multiple stations, where each station performs a specific task, and the product moves forward through the stations until it is complete. If one station is slower than the others, it will become a blocker. Product will start to queue up behind it, and downstream stations will become starved. So production lines only work well if they are planned to enable a consistent flow.
What’s more, you can only sell the product when it is completed, so we could describe the product as having no value until it is finished and with the customer.
It’s not just about manufacturing
The processes born out of manufacturing also work really well for other industries. I would suggest most things can be described like a production line, and as soon as you do that, a similar approach can be adopted to identify and fix the constraints.
Tech is an obvious one, and variations on DevOps have grown in popularity because of that. My sister in law works in a medical practice, and we’ve discussed the processes used in the administration side of it. As a result of our discussions she’s started to use Kanban boards to visualise the flow of work.
Back to my problem
So with the concept of production lines and constraints in mind, we jump back to my problem…
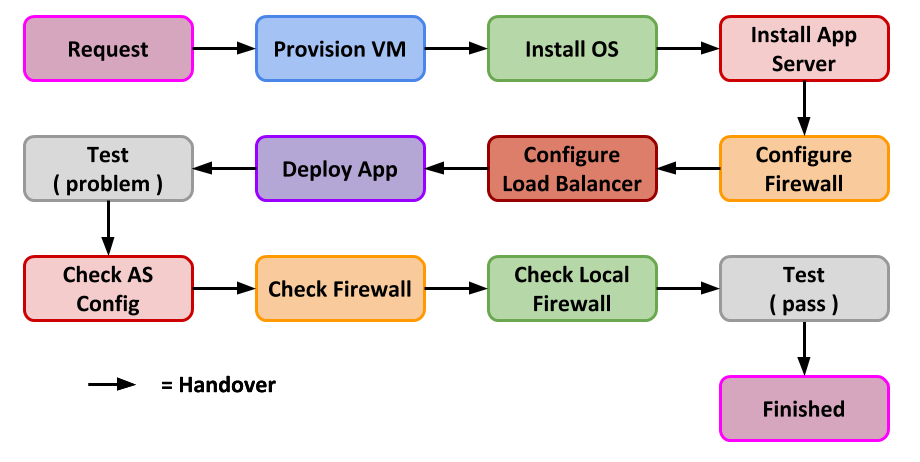
We are in the process of replacing loads of Oracle Linux 7 servers with either Oracle Linux 8 or Oracle Linux 9, depending on vendor support. The first three links in that production line are as follows.
- VMs are provisioned.
- Operating system customisations are run.
- Database or app server is installed and configured.
We are not perfect, but we’ve got pretty good at this part of the production line. When we are finished, the systems have to be tested, and go through various processes to get them live and used by the business. Those parts of the production line that follow us are slow due to a number of factors. So our improvements in the production line have just made things harder for those steps that follow us. A simplified view of the Kanban board looks something like this.
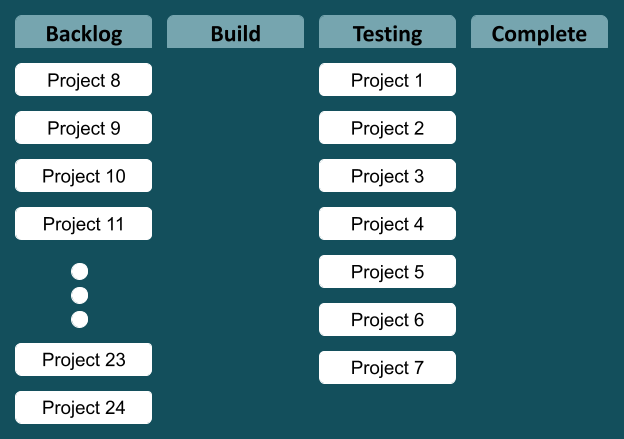
The obvious thing to do here is focus on the constraints and start working on downstream links in the chain, to improve the overall flow. That’s where we hit organisation and culture barriers, so we are pretty much stumped…
Thoughts
I’m pretty happy with what we’ve done over the last few years. We’ve definitely improved several aspects of our systems because of automation, but at the same time I can’t help thinking we’ve achieved nothing because ultimately the work is not getting completed as fast as it’s started.
I wrote here about reframing the goal, and I have to do that as copium. Unfortunately copium only goes so far… 🙂
Cheers
Tim…