The executive summary in both cases is, if you have defined workloads that don’t require elastic resource allocation, and you are not making use of cloud-only platforms, you might find it significantly cheaper to run your systems on-prem compared to running it in the cloud.
With reference to the first article Freek D’Hooge responded with this.
“I agree that cloud is not always the best or most cost effective choice, but I find the article lacking in what it really takes to run on-prem equipment.”
“Yes. On-prem works well if you have Infrastructure as Code and have automated all the crap, making it feel more like self-service.
For many people, that concept of automation only starts after they move to the cloud though, so they never realise how well on-prem can work…”
I’m assuming these folks who are moving back to on-prem are doing the whole high availability (HA) and disaster recovery (DR) thing properly.
There are many counter arguments, and I don’t want to start a religious war about cloud vs on-prem, but there is one aspect of this discussion that doesn’t seem to be covered here, and that is automation.
But you still have to automate!
Deciding not to go to the cloud, or moving back from the cloud to on-prem, is not an excuse to go back to the bad old days. We have to make sure we are using infrastructure as code, and automating the hell out of everything. I’ve mentioned this before.
Of course, servers in racks are a physical task, but for most things after that we are probably using virtual machines and/or containers, so once we have the physical kit in place we should be able to automate everything else.
Take a look at your stack and you will probably find there are Terraform providers and Ansible modules that work for your on-prem infrastructure, the same as you would expect for your cloud infrastructure. There is no reason not to use infrastructure as code on-prem.
For many people the “step change” nature of moving to the cloud is the thing that allows them to take a step back and learn automation. That’s a pity because they have never seen how well on-prem can work with automation.
Even as I write this I am still in the same situation. I’m currently building Azure Integration Services (AIS) kit in the cloud using Terraform. I have a landing zone where I, as part of the development team, can just build the stuff we need using infrastructure as code. That’s great, but if I want an on-prem VM, I have to raise a request and wait. I’ve automated many aspects of my DBA job, but basic provisioning of kit on-prem is still part of the old world, with all the associated lost time in hand-offs. For those seeking to remain on-prem, this type of thing can’t be allowed to continue.
In summary
It doesn’t matter if you go to the cloud or not, you have to use infrastructure as code and automate things to make everything feel like self-service. I’m not suggesting you need the perfect private cloud solution, but you need to provide developers with self-service solutions and let them get on with doing their job, rather waiting for you.
After my previous post on using ChatGPT to write code, I just wanted to say a few words about using artificial intelligence (AI) to generate content such as articles and blog posts.
I’ll list a few specific issues and give my comments on them.
Using AI for inspiration
I watched a video by Marques Brownlee discussing the Bing integration of ChatGPT (here), and one of the things he mentioned was using AI for inspiration. Not expecting AI to create a whole piece of work for you, but using a chat with the AI to come up with ideas.
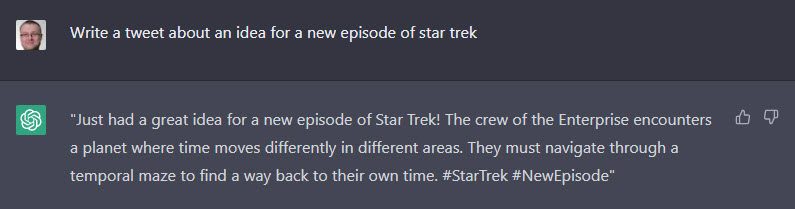
It reminded me of one of my first attempts at using ChatGPT, which was this. 🙂
Write a tweet about an idea for a new episode of star trek
If I were really trying to write something original, I might use this as the inspiration to create my own piece of work.
It should be noted, when I tweeted about this someone replied to say it was similar to the plot of a film they had seen, so we need to be careful the AI is not just stealing someone else’s idea. 🙂
I have no problem with people using AI as part of the generation of ideas. Just be careful that the ideas you get are vaguely original. 🙂
Turning bullet points into prose
One of my friends works for a company that ships physical products. The company has a paper catalogue, as well as an online store. He gets product details from the manufacturers and needs to pretty them up for use in their catalogue and website. He told me he is now using ChatGPT to do this.
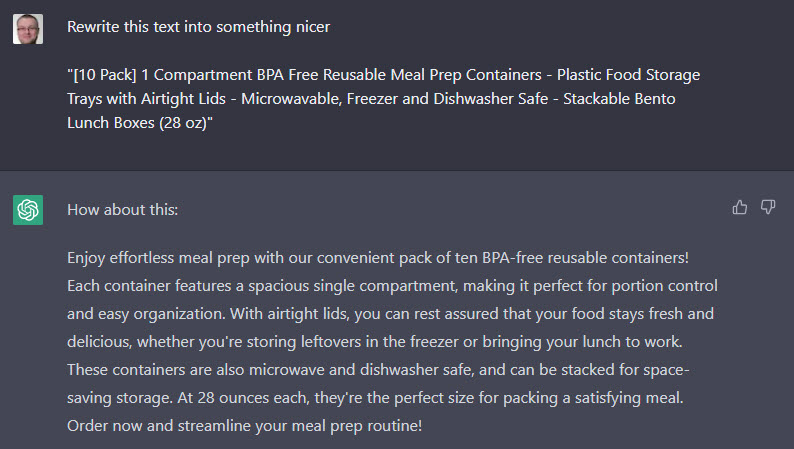
To give you an idea of what he is doing I copied some text of Amazon and asked ChatGPT to make it a bit nicer.
Rewrite this text into something nicer
In this case we aren’t expecting the AI to get facts from the internet. We are providing the base information and using the AI as a writing aid.
This is another use case I think it totally fine. It’s merely a tool that saves you a bit of time. People already use tools like Grammarly to help with spelling and grammar. This just seems like a logical next step to me.
It makes mistakes
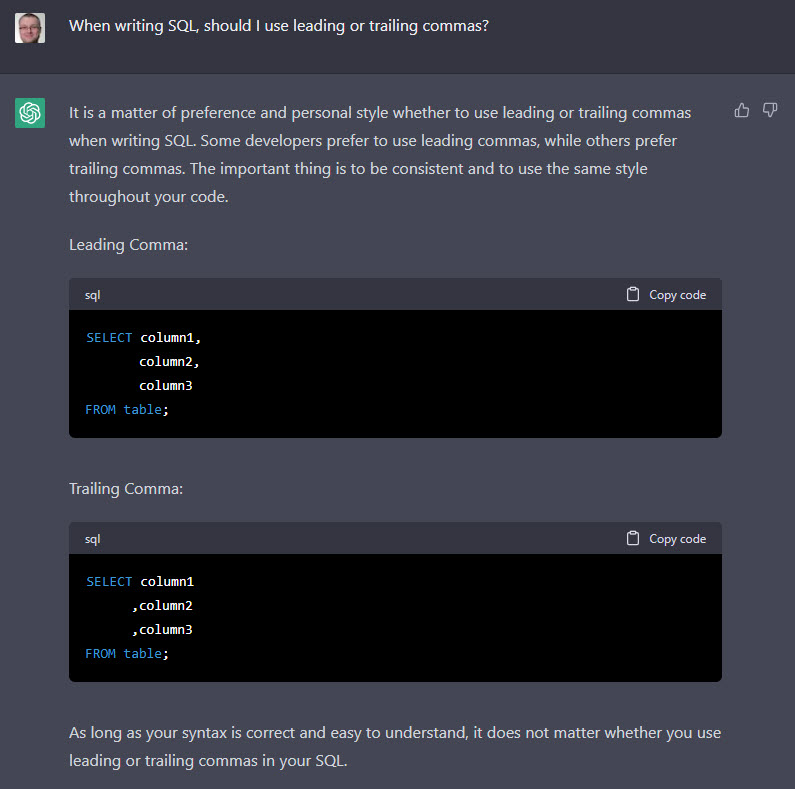
The AI doesn’t know anything about the content it is generating, so it can’t fact check itself. Here’s another example of something I Tweeted out. I asked ChatGPT if I should use leading or trailing commas when writing SQL.
When writing SQL, should I use leading or trailing commas?
It came back with a nice answer saying it is a personal preference, and gave an example of the two styles. The slight problem was the examples demonstrate the opposite of what they are meant to. 🙂
A human can pick that up, correct it and we will get something that seems reasonable, but it proves the point that we can’t blindly accept the output of AI content generation. We need to proof read and fact check it. This can be difficult if it doesn’t cite the sources used during the generation.
Sources and citations
Currently ChatGPT is based on a 2021 data set. When we use it we get no citations for the sources of information used during the generation process. This causes a number of problems.
It makes it hard to fact check the information.
It is impossible to properly cite the sources.
We can’t read the source material to check the AI’s interpretation is correct.
We can’t make a judgement on how much we trust the source material. Not all sources are reputable.
We can’t check to see if the AI has copied large pieces of text, leaving us open to copyright infringement. The generated text is supposedly unique, but can we be certain of that?
The Bing integration of ChatGPT does live searches of the internet, and includes citations for the information sources used, which solves many of these problems.
Copyright
AI content generation is still fairly new, but we are already seeing a number of issues related to copyright.
There are numerous stories about AI art generation infringing the copyright of artists, with many calling for their work to be opted out of the training data sets for AI, or to be paid for their inclusion. There is a line between inspiration and theft, and many believe AI art generation has crossed it. It’s possible this line has already been crossed in AI text generation also.
There is also the other side of copyright to consider. If you produce a piece of work using AI, it’s possible you can’t copyright that piece of work, since copyright applies to work created by a human. See the discussion here.
You can argue about the relative amounts of work performed by the AI and the human, but it seems that for 100% AI generation you are skating on thin ice. Of course, things can change as AI becomes more pervasive.
Who is paying for the source material to be created?
Like it or not, the internet is funded by ad revenue. Many people rely on views on their website to pay for their content creation. Anything that stops people actually visiting their site impacts on their income, and will ultimately see some people drop out of the content creation space.
When Google started including suggested answers in their Google search results, this already meant some people no longer needed to click on the source links. ChatGTP takes that one step further. If it becomes common place for people to search on Bing (or any other AI backed search engine), and use the AI generated result presented, rather than visiting the source sites, this will have a massive impact on the original content creators. The combination of this and ad blockers may mean the end for some content creators.
If there is no original content on the internet, there is nothing for AI to use as source material, and we could hit a brick wall. Of course there will always be content on the internet, but I think you can see where I’m going with this.
So just like the copyright infringement issues with AI art, are we going to see problems with the source material used for AI text generation? Will search engines have to start paying people for the source material they use? We’ve already seen this type of issue with search engines reporting news stories.
The morality of writing whole posts with AI
This is where things start to get a bit tricky, and this is more about morality and ethics, rather than content.
Let’s say your job is to write content. Someone is paying you to spend 40 hours a week writing that content, and instead you spend a few minutes generating content with AI, and use the rest of the time to watch Netflix. You can argue you are delivering what is asked of you and making intelligent use of automation, or that you are stealing from the company because you are being paid for a job you are not doing. I’m guessing different people will have a different take on this from a moral perspective.
Continuing with the theme of being paid to write, what if the company you are working for is expecting to have copyright control over the work you produce? If it can be determined it is AI generated, they can’t copyright it, and that work can be republished with no comeback. I can see that making you rather unpopular.
Education establishments already use software to check for plagiarism. The use of AI is already making educational establishments nervous. OpenAI, the creators of ChatGPT, have already created an AI Text Classifier (discontinued) to identify text that has been generated by AI. I can only imagine these types of utilities will become common place, and you could find yourself in hot water if you are passing off AI generated work as your own. You will certainly lose your qualifications for doing it.
Many people use their blogs as an indication of their expertise. They are presenting themselves as well versed in a subject, which can then lead to other opportunities, such as job offers, invitations to conferences and inclusion in technology evangelism programs. If it becomes apparent the content is not your own work, it would seem logical that your professional reputation would be trashed, and you would lose some or all of the benefits you have gained.
Conclusion
There is no right and wrong answer here, but in my opinion it’s important we use AI as a tool, and not a mechanism to cheat. Where we draw the line will depend on the individual, and the nature of the work being done. Also, it’s possible that line in the sand will change over time…
I’ve been having a play with ChatGPT over the last few weeks, and I wanted to give a little example of using it to try and write some PL/SQL code. Importantly, I wanted to know how close it would get to generating runnable code against an Oracle database.
Calling a web service from PL/SQL
Let’s start by asking it a pretty straight forward question.
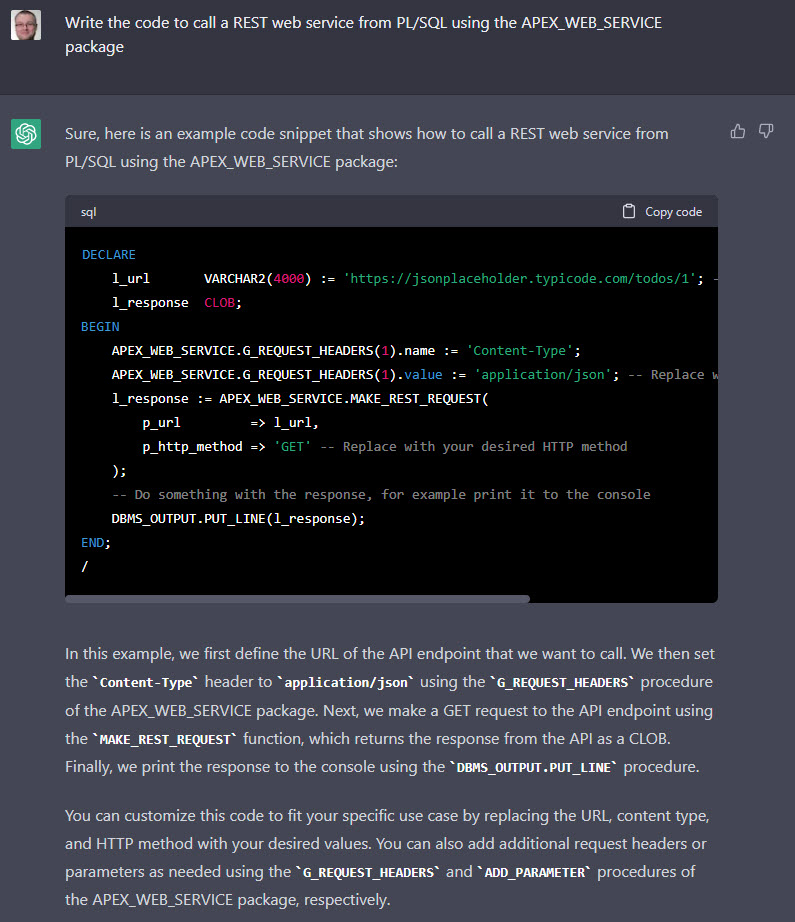
Question: Write the code to call a REST web service from PL/SQL using the APEX_WEB_SERVICE package
I think that’s pretty impressive, and not much different to my own example on the website. If someone gave me that answer in an interview question I would think they had done a reasonable job, but does it work? Not without some additional stuff.
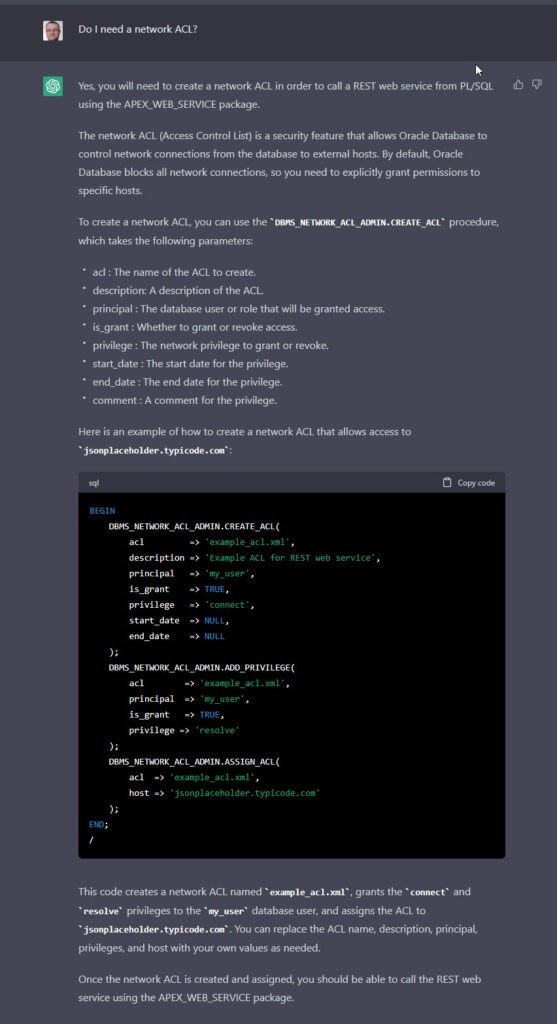
What about the network ACL?
The first issue is it doesn’t mention we need to create a network ACL to allow us to make a callout from the database.
Does ChatGPT understand we need an ACL? Let’s see. I ask it about the ACL, and it gives me an explanation of using an ACL.
Question: Do I need a network ACL?
It’s using the pre-12c syntax, but let’s create it with the correct values.
conn sys/SysPassword1@//localhost:1521/pdb1 as sysdba
BEGIN
DBMS_NETWORK_ACL_ADMIN.CREATE_ACL(
acl => 'jsonplaceholder.typicode.com_acl.xml',
description => 'Example ACL for REST web service',
principal => 'APEX_220200',
is_grant => TRUE,
privilege => 'connect',
start_date => NULL,
end_date => NULL
);
DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE(
acl => 'jsonplaceholder.typicode.com_acl.xml',
principal => 'APEX_220200',
is_grant => TRUE,
privilege => 'resolve'
);
DBMS_NETWORK_ACL_ADMIN.ASSIGN_ACL(
acl => 'jsonplaceholder.typicode.com_acl.xml',
host => 'jsonplaceholder.typicode.com'
);
END;
/
I would normally prefer to use the 12c+ syntax, shown below, but we will continue with what ChatGPT suggests rather than using the newer syntax.
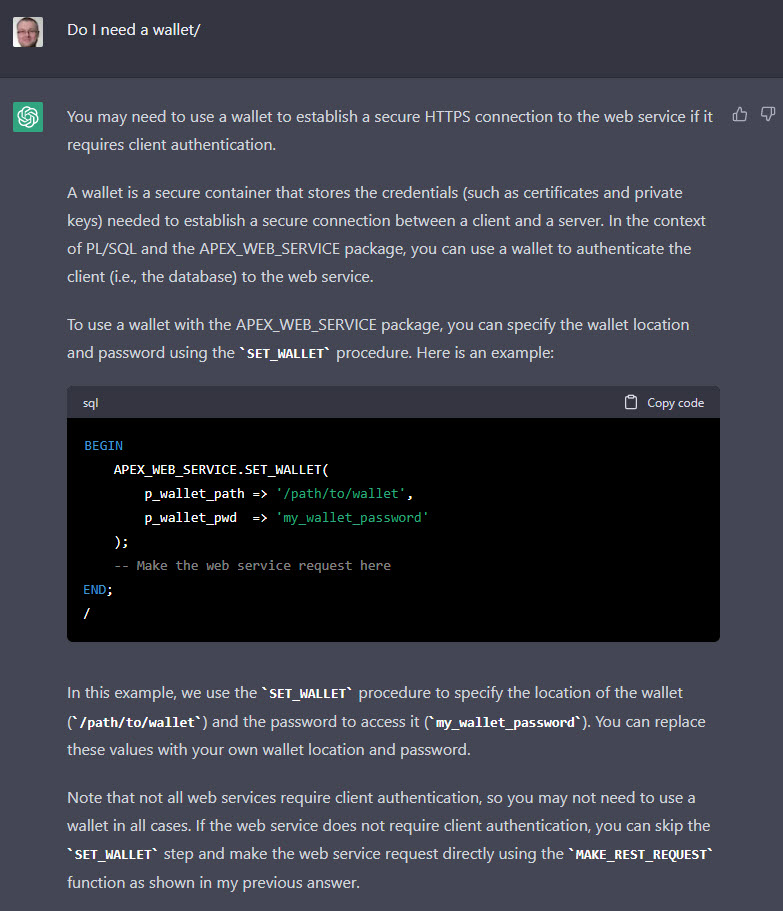
The next issue is it doesn’t tell us to create a wallet to hold the root certificate for the URL. It’s using a HTTPS address, so I have to use a wallet. I downloaded the root certificate from the site and put it in the “/tmp” location on the database server, then created the wallet as follows.
Because it didn’t tell me the wallet was needed, it also neglected to tell me the P_WALLET_PATH parameter was necessary in the MAKE_REST_REQUEST call.
Does ChatGPT understand we need a wallet? I ask it about the wallet, and include a typo. 🙂 It didn’t care about the typo, and still gave us an answer. It doesn’t tell us how to create the wallet itself, and it thinks the SET_WALLET procedure is in the APEX_WEB_SERVICE package, but it’s in the UTL_HTTP package.
Question: Do I need a wallet?
I feel like that is a fail. Not only did is get the wrong package name, but we would typically use the P_WALLET_PATH parameter with APEX_WEB_SERVICE. Even so, it might give us a clue about where to look next.
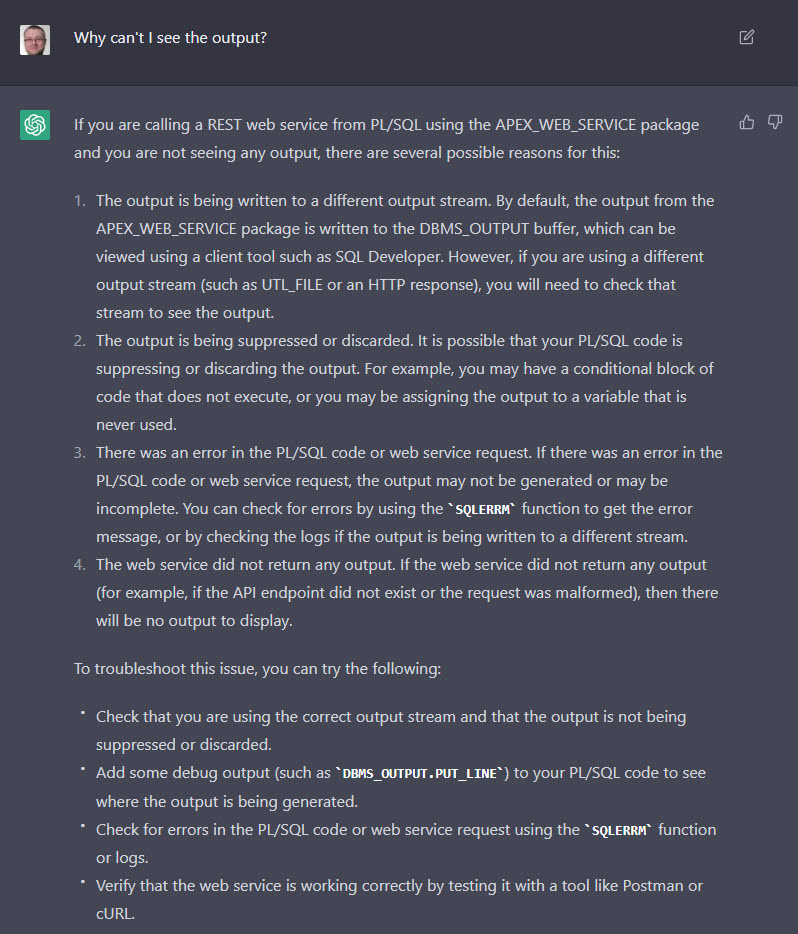
What about the output from the DBMS_OUTPUT package?
Finally, it didn’t tell use to turn on serveroutput to display the output from the DBMS_OUTPUT.PUT_LINE call. If this code was called from an IDE that might not matter, but from SQL*Plus or SQLcl it’s important if we want to see the result. I asked ChatGPT why I couldn’t see the output and it produced a lot of text, that kind-of eluded to the issue, but didn’t flat out tell us what to do.
Question: Why can’t I see the output?
Did the final solution work?
With the ACL and wallet in place, adding the P_WALLET_PATH parameter to the MAKE_REST_REQUEST call and turning on serveroutput, the answer is yes.
conn testuser1/testuser1@//localhost:1521/pdb1
set serveroutput on
DECLARE
l_url VARCHAR2(4000) := 'https://jsonplaceholder.typicode.com/todos/1'; -- Replace with your API endpoint
l_response CLOB;
BEGIN
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).name := 'Content-Type';
APEX_WEB_SERVICE.G_REQUEST_HEADERS(1).value := 'application/json'; -- Replace with your desired content type
l_response := APEX_WEB_SERVICE.MAKE_REST_REQUEST(
p_url => l_url,
p_http_method => 'GET', -- Replace with your desired HTTP method
p_wallet_path => 'file:/u01/wallet'
);
-- Do something with the response, for example print it to the console
DBMS_OUTPUT.PUT_LINE(l_response);
END;
/
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
PL/SQL procedure successfully completed.
SQL>
Thoughts
Overall it is pretty impressive. Is it perfect? No.
The interesting thing is we can ask subsequent questions, and it understands that these are in the context of what came before, just like when we speak to humans. This process of asking new questions allows us to refine the answer.
Just as we need some “Google-fu” when searching the internet, we also need some “ChatGPT-fu”. We need to ask good questions, and if we know absolutely nothing about a subject, the answers we get may still leave us confused.
We get no references for where the information came from, which makes it hard to fact check. The Bing integration does include references to source material.
Currently ChatGPT is based around a 2021 view of the world. It would be interesting to see what happens when this is repeated with the Bing integration, which does live searches of Bing for the base information.
When we consider this is AI, and we remember this is the worst it is ever going to be, it’s still very impressive.
It’s an age old story. Your company wants to adopt some new tech stuff, but they set themselves up to fail. It doesn’t matter what we are talking about, it always happens because of one or more common traps.
Ignoring the learning curve
It takes time to become proficient at something new, but companies often don’t see this skilling up time as “productive”. They want to see results as soon as possible. This often means you will rush stuff out to production without a complete understanding of what you are doing, which then has one of several knock-on effects, most of which are negative.
I’m not suggesting you should wait until everyone is an expert, but there has to be some sensible effort to skill up before launching into production work. That’s typically not a one week course then go, and it’s also not a one week course, followed by a six month gap, then go.
Iterative development fails
In an attempt to counter the problem with the learning curve you try to work on an iterative basis. That way you can take stock at regular intervals, understand what is working and what is not, then go through a process of refactoring to bring everything in line with your new understanding. In the end you should get to the right place, but see the next section.
There is nothing wrong with iterative development itself. The problem comes from when it is applied badly. True of many things.
Refactoring is not productive work
Imagine the scenario.
You: In the process of doing the last couple of projects we’ve learned so much. Mostly how wrong we got things. We need to go through and refactor all the existing code to bring it into line with our current approach.
Company: What do we get out of this?
You: Well it will allow us to apply our current best practices and make the code more future proof and supportable.
Company: But will we get any new functionality? New screens? New shiny things?
You: No.
Company: So about these new top priorities we want you to work on. They are really shiny!
You: But what about the refactoring?
Company: Yeah, that’s not going to happen. Add it to the list of technical dept.
Because refactoring delivers nothing new in the eyes of many people in the business, it is considered really low priority. Despite the good intentions of iterative development, the amount of crap keeps piling up until you reach a breaking point. Unless you can schedule in time for internal projects to clean up technical dept, you are building up failures for the future.
We’ll get in some consultants to help us
One option is to get some people with the prerequisite experience to help you deliver the new tech. The idea being those people can hit the ground running, and start knowledge spreading to help your company adopt the new tech more quickly.
In theory this is a great idea, but how many times have you seen this fail? The consultants are hired to do the work, given deadlines that leave no time for knowledge spreading, and leave once their contract is up. At best you have a working product you can look at and use for inspiration, but often you are left with a half-baked solution you would like to scrap and rewrite yourself.
This is not a criticism of the consultants. Often it is a garbage in, garbage out situation. It takes time to learn the vocabulary to be able to discuss the issues properly, know what questions to ask, and communicate your requirements. For bleeding edge tech you might be paying someone to learn for you, with all the problems that entails.
Making everything match your existing company structure
Many companies have a company structure with siloed teams taking on specific roles. Each team acting as a gatekeeper for that specific part of the tech stack. On paper it seems to make the teams more efficient, see efficiency paradox, but in reality it results in endless amounts of lost time in hand-offs between teams, waiting for tickets to be processed. See Conway’s Law.
When you are trying something new, you have to consider that your existing team structures may not work well with that new tech. Trying to force it into your existing structure may cause it to fail, or at least not deliver the benefits you expected. This is one of the reasons why cloud, DevOps and automation have been so problematic for many companies, as they blur the lines between existing silos.
As I’ve mentioned in previous posts, silos aren’t totally evil. They can work just fine as long as they deliver value through services, allowing users to work in a self-service manner. The problems come when you are waiting on a ticket to be processed to get what you need.
You don’t really want to change
Unfortunately there are a lot of people that talk a good talk about change, but ultimately don’t really want to change. They will either knowingly sabotage projects, or unknowingly sabotage them through inaction.
The only way change can happen is if senior management understand the need for change, and push everyone in that direction. No amount of personal heroics can solve the problems of a company culture that won’t accept change. If your company has a problem, it is 100% the fault of senior leadership.
Conclusion
There are lots of reasons why new initiatives fail. Companies are quick to blame the failures on external factors, but rarely put themselves in the spotlight as being the cause of the failure. There is very little in technology that is universally good or bad. The devil is in the detail!
I’ve been toying with writing this post a few times over recent years, but each time I’ve backed off. Recent events have brought it to the fore again, so I thought I would give it a shot…
In the beginning
I guess when I was first starting out in the working world I was a little naive and felt like work was my extended family, and they cared about me. Over the years a number of events brought me to the realization that I am just a commodity. I am selling my time for cash. The company wants to get as much of my time as they can, for as little money as possible. We are sold a story that the harder we work, the bigger the returns will be, but that’s not always true and you have to ask yourself what you are willing to give up for a chance at a possible return in the future that might never come.
The pandemic and quiet quitting
The pandemic caused a really big shift in the way many people perceived work. Prior to the pandemic many of us were lost in the grind. Once we started working from home we realized there was such a thing as work-life balance. That was one of the factors that lead to “quiet quitting”, which is an unhelpful name for what is essentially setting boundaries.
If you are hired to work a normal working day, let’s say 9 to 5, why would you start earlier or work later for no extra benefits? Why not disconnect from work as soon as the clock strikes 5 and live your life? If there is a pressing deadline, is that really your problem, or was the project not staffed properly? If there is a problem at the weekend, shouldn’t the company hire people to provide support over the weekend, rather than expecting you to chip in and help?
You as an individual have to set boundaries and stick to them. I’ve been terrible at this over the years, seeing myself get sucked in to doing more and more.
If you are being paid to do a job, it is only right that you do it to the best of your ability, but that doesn’t mean working excessive hours, and spending your free time thinking about it.
Productivity and pay
Another thing that can cause consternation is the relationship between productivity and pay, or the lack of it. I’ve worked for some companies where people get paid different amounts of money for the same job, based on their perceived productivity. I say “perceived” as some people are really good at faking productivity (see Visibility vs Results). If productivity is tracked and managed properly, I have no problem with people being paid different amounts of money for the same job. People are being paid based on the value they provide to the company.
There are companies where the pay scales are quite rigid. Everyone doing job X gets paid the same money, regardless of productivity. What happens if Jayne is twice as productive as Janet? Effectively Jayne is being paid half the amount of money per unit work delivered. That begs the question should Jayne work less hours, so she completes the same units of work as Janet over the week? I’m pretty sure many companies would say no, because they want the most out of the workers for the least amount of money, but if there is no incentive to be more production, why bother?
Working from home
Working from home has become another bone of contention. Before the pandemic I could never have imagined working from home full time. Now it is one of my requirements for any future job. I see no reason why I should be stressed out by a commute ever again. I speak to colleagues who are saving massive amounts of time and money by not having to commute. Forcing people into an office when they don’t want to be there is a very negative situation…
The view of business types
I keep seeing stories by business types complaining people aren’t willing to put in the effort these days. Why is it a problem? They want you to work harder so they can employ fewer people and make bigger profits. They don’t care about the impact on the people or their work-life balance. It’s just a meat grinder.
Here’s a quote from Jeff Bezos.
“When I interview people I tell them, ‘You can work long, hard, or smart, but at Amazon.com you can’t choose two out of three,”
Bezos wrote in the 1997 letter.
More recently we’ve had Elon Musk coming out with phrases like these.
“extremely hardcore” “long hours at high intensity” “only exceptional performance will constitute a passing grade”
Elon Musk during the Twitter debacle.
They are both seeking something for nothing, and they don’t give a crap about the people they burn out and discard along the way…
You scratch my back, I’ll scratch yours
Companies have to understand that jobs are a balancing act. Some people want more money, while others place more value on their free time. What’s more, that balance changes over time. I’ve seen this shift in myself over the years.
Conclusion
It’s not up to me to decide how you should live your lives, but don’t for one moment think companies care about you. Sure, some individuals in the company might, but ultimately you are a cog in a money making machine, and when it suits them, they will turn on you.
Know what you are worth, and understand what you value in life!
I’ve installed it on Windows 10 and 11 machines with no drama. I’ve also run Packer builds of all my Vagrant boxes, which you can find on Vagrant Cloud here.
Life has been a little quiet on the publishing front recently. You may have noticed I’ve not posted many new articles or blog posts of late. This situation is likely to continue for some time, and I thought I would drop a post to let you know why…
I’m currently spending most of my time playing with a certain beta product, and all of that is covered by a non disclosure agreement (NDA). Over the last few weeks I’ve written a bunch of articles, but I can’t hit the publish button on them yet. Over the coming months I’ll continue to write new articles and give feedback to Oracle, but of course you will not be seeing any of this.
Once the product goes live I’ll be able to release all this stuff, with the obligatory edits/rewrites to take account of the changes between the beta and live versions of course. The total amount of content will be no different in the long run, but there will be a baron period for a few months followed by a glut of content. I suspect this situation will be similar for a number of folks in the Oracle community.
The rules are a bit different for Oracle employees, so you will be seeing teasers for new functionality from them, but not from the rest of the community…
Over the next few months I’ll mostly be posting memes and “from the vault” links on social media, just so you don’t forget I exist, but it is going to be a relatively quiet time…
I realise the world is a big place and depending on which hemisphere you live in, the scene you associate with this time of year will be quite different.
I just wanted to say have a great holiday break. Be safe and enjoy yourselves! If you have a little spare cash or spare time, please try to help out some people who are not as fortunate as yourself! It doesn’t take much to make a big difference!
Day 2 started pretty much the same as day 1. I arrived late to avoid the traffic.
The first session I went to was Martin Nash with “Oracle Databases in a Multicloud World”. I was a bit late to this session, but from what I saw it seemed the general view was “don’t be stupid, stupid”. Multi-cloud can add some complexity and latency, but if it’s what you need, it’s all manageable. If you do have a system where multi-cloud is not suitable, don’t do it for that system. Most things can be migrated, but some things are easier than others. Pick your fights. Sorry if I came to the wrong conclusion… 🙂
I often get the feeling that some people think everything has to be all or nothing. We have Oracle Cloud Apps on Oracle Cloud. A bunch of stuff on Azure, with more to come. One of our major systems is moving to AWS in the next couple of years. Then of course we still have a load of stuff on-prem. This isn’t because we are desperate to be multi-cloud. It’s just the way things have happened. I’m sure we’ll run into some issue along the way, but I’m also sure we’ll solve them. Once size does not fit all…
BTW Martin now works for Google, so we have to hate him. 🙂
Next up was Jasmin Fluri with “The Science of Database CI/CD”. I already had the long form of this presentation because I read Jasmin’s masters thesis, but I was interested to see how she summarised some of it into a presentation. She did a great job of getting the main points into a 45 minute session, which can’t have been easy. It was also a little depressing, because I’ve come a long way , but I’ve still got such a long way to go. Ah well…
After Jasmin was Erik van Roon with “Scripting in SQLcl – You Can Never Have Enough of a Good Thing”. The session discussed how to extend the functionality of SQLcl with your own commands written in JavaScript. I get the distinct impression Erik has too much time on his hands. If anyone wants to join me in staging an intervention, just let me know. 🙂 I’m not sure if I will use this functionality, but it’s always good to know it exists, because you never know when it might come in handy, and knowing it’s possible is the first step.
Last up for me was “The Death of the Data Scientist, But Long Live Data Science” by Brendan Tierney. To summarise Brendan talked about the recent mass layoffs of data scientists, suggesting a number of factors including a glut of data scientists on the market, low return on investment from many data science teams, and the simplification and automation of data science to the point where it had now been integrated into products and domain-specific staff roles. It’s typical hype cycle stuff. We’ve moved from the “Peak of Inflated Expectations” to the “Trough of Disillusionment”, and the job market has corrected itself because of that. It doesn’t sound like a move from DBA to data scientist is a great career move right now. 🙂
I spent some time chatting to Brendan, then it was off to beat the traffic home so I could return to real life again.
UKOUG Breakthrough 2022 is over now, and it was a good introduction back into the world of face to face conferences for me. I’m still very nervous about the thought of travelling, but based on the last few days I’m hoping I can get my conference mojo back. Just don’t expect too much too soon. 🙂
Thanks to all the conference organisers and speakers for giving up their time to make this happen. See you all again soon.
The evening before the conference the Oracle ACEs met up for some food at a curry place in the city centre. Thanks to the Oracle ACE Program for organising this! Earlier that day I presented my first face to face session in 3 years, and now it was time for my first social event in a similar timescale. I was pretty nervous going into it, and quite standoffish at first, but I gradually relaxed and “conference Tim” started to come back. By the end of the evening I was feeling a lot more comfortable with the situation. It was nice to get to meet up with a bunch of people I had not seen for a long time. It also made me feel a bit more relaxed about going to the conference the next day.
The one downside of going to a conference in your hometown is commuting. I don’t live far away from the venue, but regardless of the mode of transportation, commuting during rush hour is a nightmare. Instead I chose to wait for the rush hour traffic to die down and be fashionably late. That was the right move.
The first session I went to was Simon Haslam speaking about “Platform Engineering for the Modern Oracle World”. I’ve got a lot of time for Simon. Him and Lonneke Dikmans sowed some seeds in my brain a long time ago, which have ultimately had a big influence on me over the years. In this session he talked about the various approaches to automation over the years, culminating in where many people find themselves today. I found myself nodding my head in agreement with most of what Simon was saying during this session. I joked later that his session gave me post traumatic stress disorder (PTSD) when I thought back through many of those stages. 😁 A group of us continued the conversation about the topic after the session, which is always fun.
Next I moved on to the Oracle ACE Briefing. The first rule of the Oracle ACE Briefing is don’t talk about the Oracle ACE Briefing. Once again, it was good to see a lot of familiar faces, and some new ones. Once the session was over, and we knew everything there was to know about the Oracle Games Console (#OGC), I spent some time talking with Dominic Giles, while he desperately looked for ways to get rid of me. He didn’t succeed. 😉
By the time I finally let Dom go, it was time to watch Jasmin Fluri and Gianni Ceresa presenting “Git Branching – the battle of the ages”, or “Development Workflows: The Battle of The Ages!”, depending on which title you prefer. The session was a celebrity death match between trunk-based development (Jasmin) and Gitflow style development (Gianni). Gianni fought dirty, but ultimately Jasmin was able to overpower him and grind him into the dirt. At least that’s how I saw it. 🙂 Both sides gave compelling reasons for their preferred method, and ultimately there is a lot more similarity between them than some people would have you believe. As is often the case, there is no “best”, but what is “best for you”. Not surprisingly, this sparked another conversation at the end of the session, with a few war stories thrown in for good measure.
At that point I had to head off to beat the traffic across town, as I had some “real life” things to do.
So that’s was day 1 of UKOUG Breakthrough 2022. I know it will sound silly to most people, but I was stressing about the conference and it turned out to be a lot easier than I expected. Fingers crossed day 2 will go well also.