Oracle have released Oracle Database 23ai. You can watch the announcement video here, and read the announcement blog post here.
I don’t think I can add much to that, but I just want to talk about how this affects me as a customer and as a content creator.
Customer View
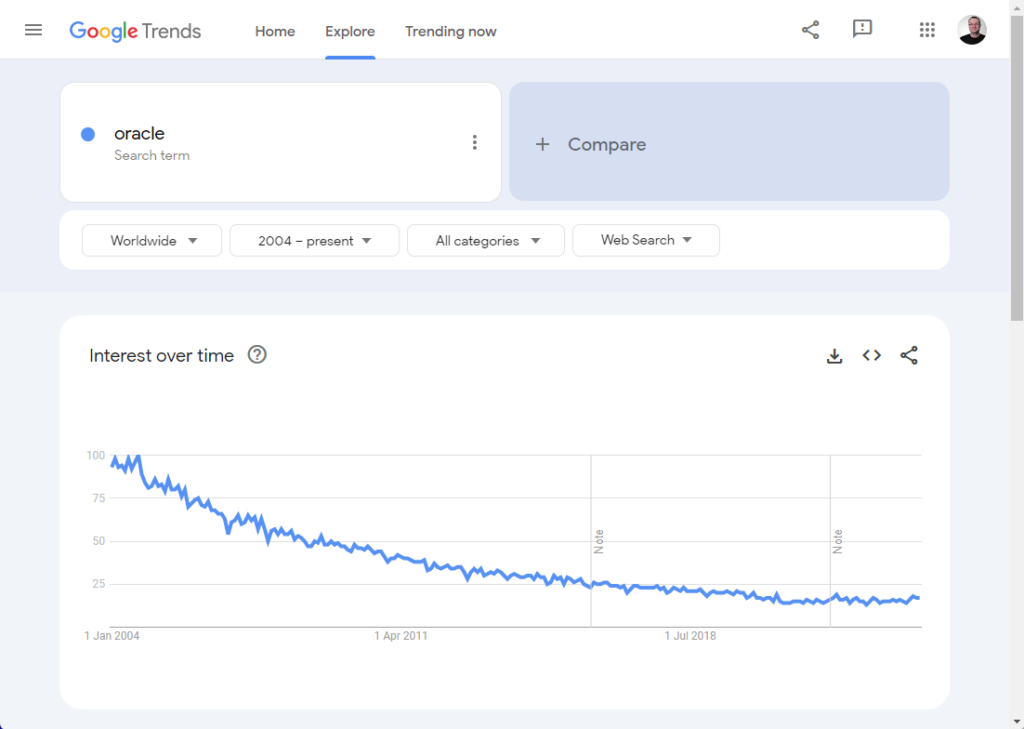
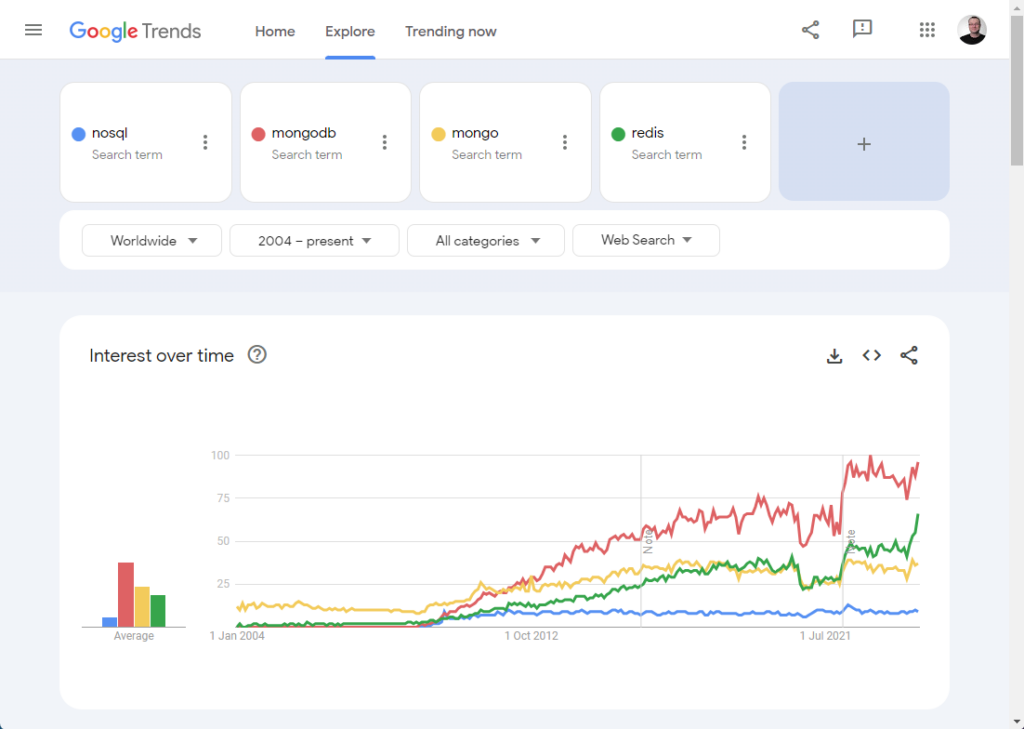
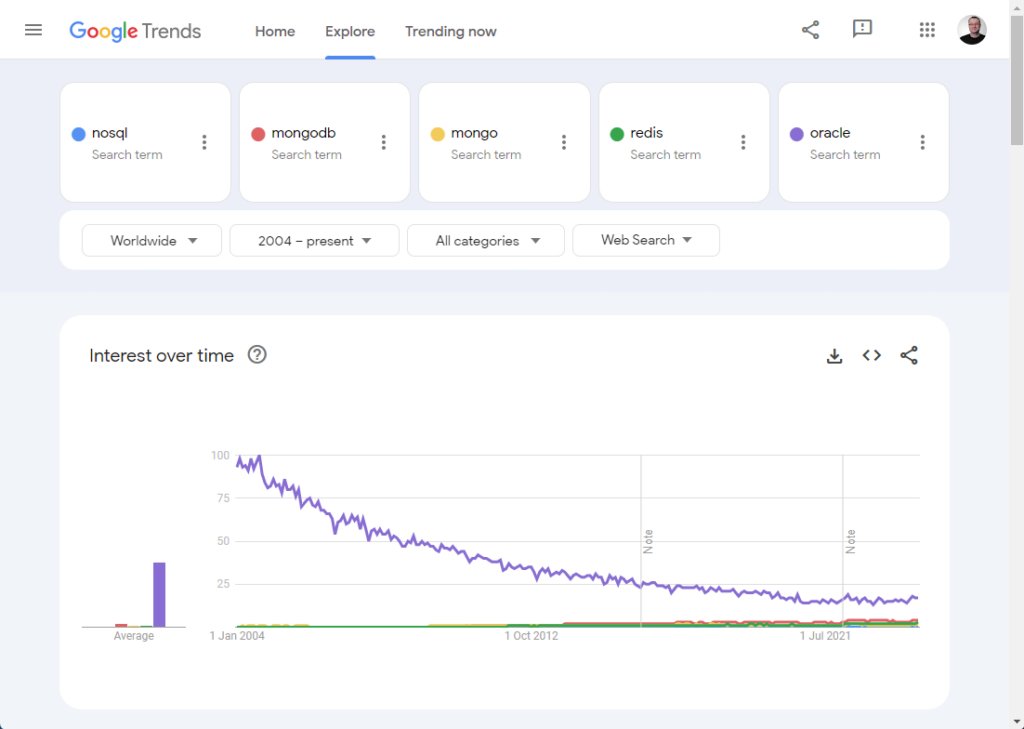
We’ve been waiting for Oracle Database 23 for a very long time. As I mentioned in this post, most of the upgrades I’ve been asked to do in my career are not driven by new features. They are driven by a need to stay in support.
Database upgrades are pretty simple from a technical perspective, but from a project perspective they are a nightmare. It takes ages to get everyone to agree to them, and then an eternity to actually test things before progressing to production. Any delays have a massive impact on this process.
We are in the process of migrating loads of our databases off Oracle Linux 7 and on to Oracle Linux 8 or 9 depending on 3rd party vendor support. We have to go through a whole testing cycle to complete this. If Oracle 23 had been released last year, many of these migrations would have gone directly to the new OS and new database version. You can argue the virtues of doing things separately or as a big bang, but our reality is testing resources are our biggest blocker, so having to test all our systems twice, once for the OS migration and once for the DB migration, represents a problem.
The delay of Oracle 23 on-prem has been a big headache. When I saw the announcement of Oracle Database 23ai I was sure it would include the on-prem version of the database. It does not. That was a bitter disappointment!
Content Creator View
I realise most of the people reading this are not content creators, and these issues are unlikely to affect you, but here goes…
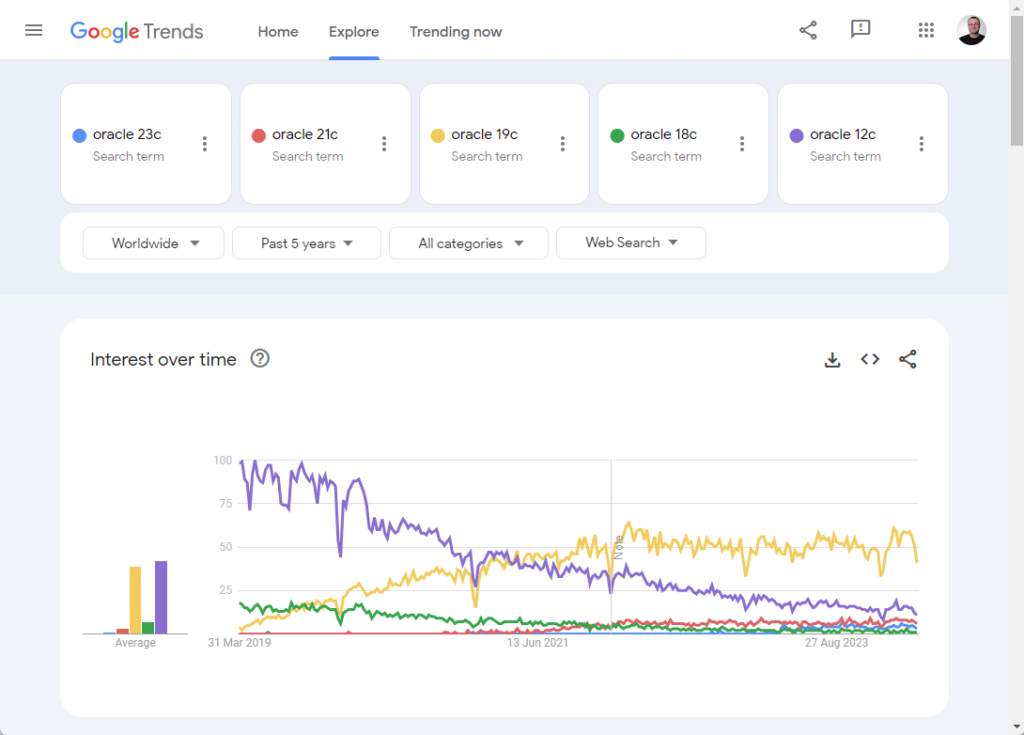
Over the last 18 months I’ve written a bunch of articles. With the release of 23c Free I was able to publish most of them. As part of the Oracle community hype machine we’ve been encouraged to produce as much content about 23c as possible. There are a lot of us that will either have to go back and edit our 23c content, or leave the internet full of content for a version that doesn’t exist.
For the most part 23ai is just 23c with a different badge, so much of this can be done with a search and replace, along with the appropriate redirects. Where it is a bigger problem is for those that have published videos on YouTube, as those need to be redone and republished. There is no quick in-place edit. I’m one of the lucky ones here, as I made the decision to wait for the on-prem release before starting any videos, but some people will have a really painful job to do if they want things to keep current.
What I’m doing now
I’ve started the process.
My 23c index page now redirects to 23ai. It still contains all the 23c articles, but over the coming weeks they will change. All the old URLs will be redirected, so the world won’t be filled with broken links. It’s just going to take some time. If any of you notice any problems, just give me a shout.
I updated my vagrant builds. The 23c Free on OL8 build is now 23ai Free on OL8 build. There is also an OL9 build. You can find them here.
- https://github.com/oraclebase/vagrant/tree/master/database/ol8_23_free
- https://github.com/oraclebase/vagrant/tree/master/database/ol9_23_free
The original article about this OL8 build has been amended, and there is a new one for OL9.
- Oracle Database 23ai Free RPM Installation On Oracle Linux 8 (OL8)
- Oracle Database 23ai Free RPM Installation On Oracle Linux 9 (OL9)
The first step on the journey…
Overall
So I’m a few steps back compared to where I was before the announcement. I’m still waiting for the on-prem release, and now I’ve got to rework a bunch of existing content…
We are already seeing some backlash against AI in the tech press. I hope the new name doesn’t come back to haunt Oracle.
Cheers
Tim…
PS. Of course it’s all my own fault.