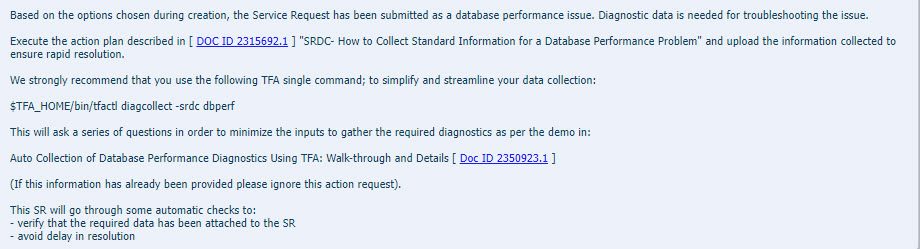
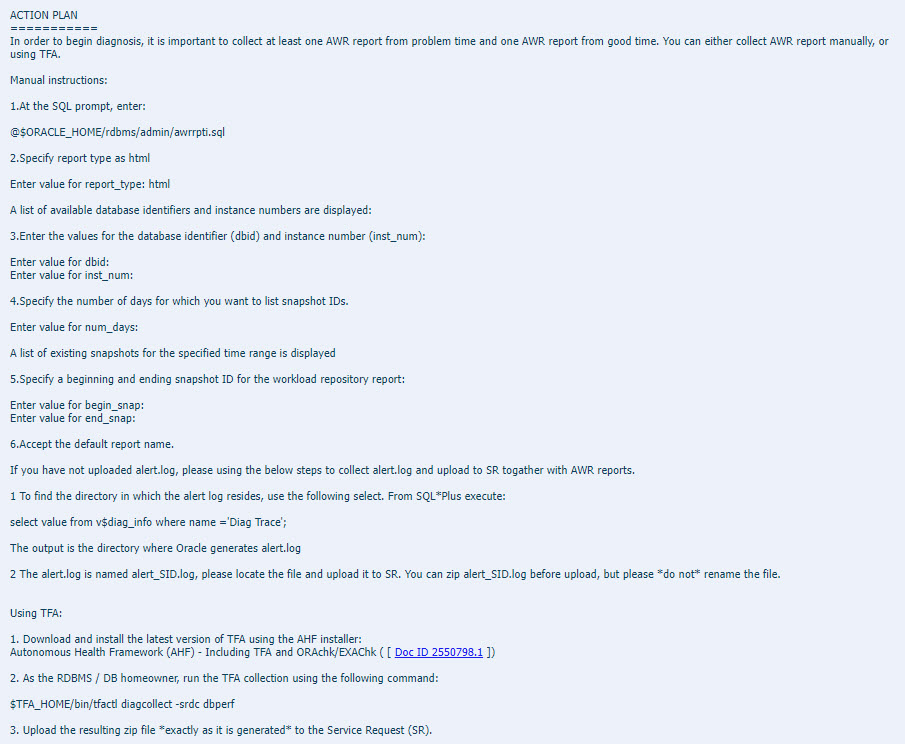
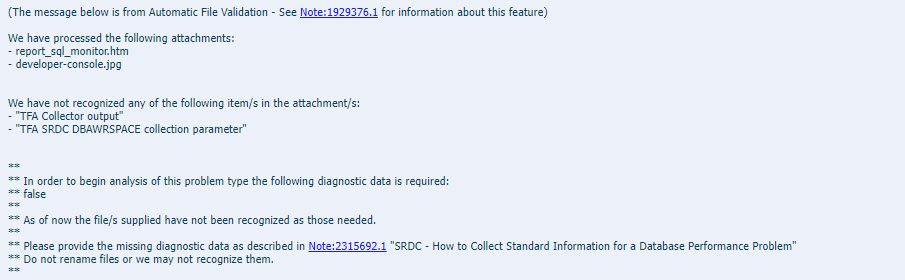
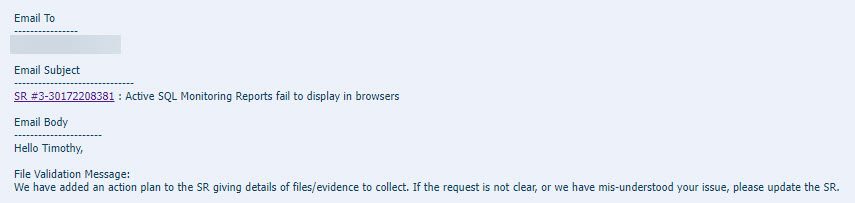
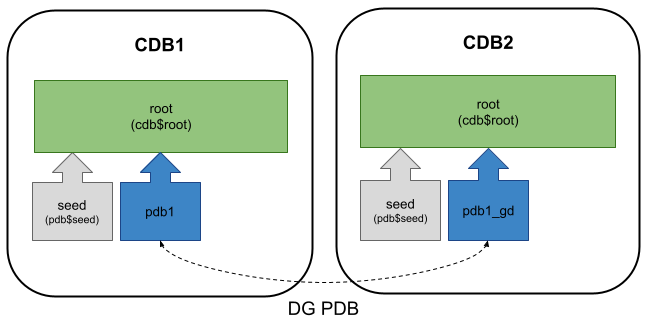
Last month you may have noticed the announcement of DG PDB. It’s Data Guard for PDBs, rather than CDBs, introduced in the Oracle 21.7 release update.
How do you use it?
I’ve had a play around with it, which resulted in this article.
I also did a Vagrant build, which includes the build of the servers, the database software installations, database creations and the perquisites, so you can jump straight to the DG PDB configuration section in the article. You can find that build here.
So that’s the basic how-to covered, and I really do mean “basic”. There is a lot more people might want to do with it, but it’s beyond the scope of my little Vagrant build.
What do I think about it?
Well I guess you know how this is going to go, based on the title of this post. I don’t like it (yet), but I’m going to try and be a bit more constructive than that.
- It is buggy! : I know 21c is an innovation release, but this is a HA/DR solution, so it needs to be bullet proof and it’s not. There are a number of issues when you come to use it, which will most likely be fixed in a future release update, or database version, but for now this is a production release and I don’t feel like it is safe pair of hands for real PDBs. That is a *very* bad look for a product of this type.
- Is it Data Guard? Really? : Once again, I know this is the first release of this functionality, but there are so many restrictions associated with it that I wonder if it is even deserving of the Data Guard name. I feel like it should have been a little further along the development cycle before it got associated with the name Data Guard. The first time someone has a problem with DG PDB, and they definitely will, they are going to say some choice words about Data Guard. I know this because I was throwing around some expletives when I was having issues with it. That’s not a feeling you want to associated with one of your HA/DR products…
- Is this even scriptable? : The “add pluggable database” step in the DGMGRL utility prompts for a password. Maybe I’ve missed something, but I didn’t see a way to supply this silently. If it needs human interaction it is not finished. If someone can explain to me what I’ve missed, that would be good. If I’m correct and this can’t be done silently, it needs some new arguments. It doesn’t help that it consistently fails the first time you call it, but works the second time. Ouch!
- Is the standby PDB created or not? : When you run the “add pluggable database” command (and it eventually works) it creates the standby PDB, but there are no datafiles associated with it. You have to copy those across yourself. The default action should be to copy the files across. Oracle could do it quite easily with the DBMS_FILE_TRANSFER package, or some variant of a hot clone. There should still be an option to not do the datafile copy, as some people might want to move the files manually, and that is fine, but to not have a way to include the file copy seems a bit crappy.
- Ease of use : Oracle 21c introduced the PREPARE FOR DATA GUARD command, which automates a whole bunch of prerequisites for Data Guard setup, which is a really nice touch. Of course DG PDB has many of the same prerequisites, so you can use PREPARE FOR DATA GUARD to get yourself in a good place to start, but I still feel like there are too many moving parts to get going. I really want it to be a single command that takes me from zero to hero. I could say this about many other Oracle features too, but that’s the subject of another blog post.
- Overall : A few times I got myself into such a mess the only thing I could do was rebuild the whole environment. That’s not a good look for a HA/DR product!
Conclusion
I’m sorry if I’ve pissed off any of the folks that worked on this feature. It wasn’t my intention. I just don’t think this is ready to be included in a production release yet. I’m hoping I can sing its praises of a future release of this functionality!
Cheers
Tim…
PS. I’m reminded of this post about The Definition of Done.